![]()
インシデント対応のためのLinuxログ入門
インシデント対応のためのLinuxログ入門
はじめに
こんにちは、ディフェンシブセキュリティ部の岩崎です。
本記事はログ全般に関すること、ログ管理がより必要なサーバに多く利用されているOSであるLinuxログに関するTipsを主にセキュリティ観点で紹介します。
これからログ分析を始める方からシステム管理者まで、日々の運用からセキュリティの向上やインシデント対応のヒントになれば幸いです。
1.そもそもログとは
2.なぜログを見るのか? ─ ログを取得・管理する目的とは)
3.ログ解析をする前に(重要)
4.Linuxサーバで見られる主なログファイル一覧
5.Linuxの主要なログファイルの解析方法について
6.実際の調査手順
ログ解析の情報だけほしい方は「4.Linuxサーバで見られる主なログファイル一覧」以降を見ていただくとよいと思います。
1.そもそもログとは
ログとは、ソフトウェア等の設計者、開発者、運用者等が特定の目的を持って、一定の出力形態により出力および記録される情報のことです。
【引用元】デジタルフォレンジック研究会(※1) が発行している証拠保全ガイドライン
(※1)「広く一般市民を対象として、情報セキュリティの新しい分野である「デジタル・フォレンジック」の啓発・普及、調査・研究事業、講習会・講演会、出版、技術認定等の事業を通じて、健全な情報通信技術(IT)社会の実現に寄与・貢献することを目的とする。」団体です。
Linuxサーバのログと言えば、一般的にはシステム管理や障害対応によるトラブルシューティングに使われるイメージがあると思います。
セキュリティ的には、上記に加え「ログはインシデント対応時の原因究明や影響範囲の調査で非常に重要な証跡」という観点が追加されます。
2.なぜログを見るのか? ─ ログを取得・管理する目的とは
一般的なログ取得・管理に対する意識
Linuxはサーバ環境で利用されることが多いです。
そのため、ログの種類も多く、記録される量も膨大です。
弊社にてご支援させていただくインシデント対応の現場では、デフォルト設定でログの取得・管理が行われているケースが少なくありません。
構築時や機能追加時には動作確認やトラブルシュートなどでログを確認する機会があるものの、安定運用されている間はログを取得・管理しているという意識なく、Linuxサーバを運用・監視している方も多いのではないでしょうか。
目的なくログ取得・管理している場合の問題点
フォレンジック調査やインシデント対応支援を行っていると、インシデントが発生したのが約2カ月前で、そのときに多くの侵害が発生しているのにも関わらず、ログが直近1ヵ月分しかない、ということが少なくありません。
ログはインシデントの侵害原因及び影響範囲を特定する上でとても重要な証跡になります。
ログがないことで、自組織の情報がどこまで守られ・どこまで侵害されているかが否定も肯定もできない状態になります。そのような状態であると、管理している情報はすべて漏えいした可能性があるとの判断をせざるを得なくなり、社会的な信用や対応費用含めて会社に大きな損失を招く結果になってしまいます。そのため、サービスが動いているからよしではなく、目的をもってログの取得・管理を行うことが重要です。
ログ取得・管理の主な目的
どのような目的でログを管理するのか、以下に5つほど紹介します。
ログ管理目的一覧
| ログ管理目的 | 詳細 |
|---|---|
| システム管理 | 平常時のシステムリソース状況の確認など、問題が発生する前の事前対策を目的としています。 |
| トラブルシューティング | 障害や不具合が発生した際の、迅速な原因の特定や復旧作業の効率化といった事後対策を目的としています。 |
| 不正検知・攻撃検知 | 不審な動きを検知するための事前対策を目的としています。 一般的にはSIEMやログ監視のシステムを用いて、リアルタイムに兆候を監視します。 |
| インシデントレスポンス(IR) | インシデント時の迅速な対応、被害の最小化、侵害範囲の明確化を目的としています。 |
| 説明責任 | 企業のコンプライアンス・法的義務を果たすことを目的としています。 比較的長期的なログを管理することがあります。 |
ログ保管日数の目安
インシデントレスポンスのためのログの保管日数は、少なくとも1年必要と考えています。 フォレンジック調査及びIRの経験上、攻撃が数か月以上(長いと3年)と続いていることが少なくありません。 そのため攻撃を長期間トレースする必要がある場合、可能な限り長期間のログ保管が必要です。
なおJPCERT/CCでは、インシデント対応支援や高度サイバー攻撃の調査等の結果から、ひとつの参考値として1年分のログの保存を推奨しています。
【参考】高度サイバー攻撃への対処におけるログの活用と分析方法 1.0版(JPCIRT)
ログ保管日数を検討するにあたって指針となる情報として以下が挙げられます。
契約や法的要求事項に対応するため、以下のようなケースで保管日数が決められている場合は、ログはすでに目的をもって取得・保管されているかと思います。
ログ保管日数指針
| ログ保管日数が定義されているもの | 説明 |
|---|---|
| 契約書・要件定義書 | SLA(サービスレベルアグリーメント)や業務委託契約においてログ保管期間が定められていることがあります。 |
| セキュリティポリシー | ログ保管規定がある場合は規定された期間以上のログを保管する必要があります。 |
| PCI DSS | EC事業者ではクレジットカード情報を扱うシステムにおいてPCI DSSへの準拠が求められます。 その中で、ログは1年保管、3か月アクティブ(閲覧できる状態)にすることが求められています。 |
推奨するログ保管方法
近年はランサムウェアによりログファイルを含むサーバ上のファイルが改ざんまたは削除されるケースも珍しくありません。
そのため、インシデント対応時に調査対象となる可能性のあるログファイルについては別サーバ等へバックアップを取得することが推奨されます。
例えば「3-2-1ルール」に則り、複数の媒体でバックアップを管理することが考えられます。
3.ログ解析をする前に(重要)
サーバの保全の実施
サーバが停止状態か稼働状態かに関わらず インシデントでログを調査する際は、可能であればディスクイメージ(DDイメージまたはE01イメージ)を取得してください。 ディスクイメージを取得することにより、サーバ上にあるすべてのファイルが保全されるだけでなく、使用していない領域(空き領域)に断片として残っているログやマルウェアも調査対象とすることができます。
サーバ上のすべてのファイル(ログや不審なファイル)を取得し別のディスク(外付けSSDなど)へコピーした場合、一部のタイムスタンプが失われます。 そのため、サーバ上のすべてのファイルを取得する保全はインシデント調査の保全作業としては推奨されません。
ディスクイメージが取得できない場合
ホスティングサービスの特徴として、ディスクイメージの取得可否や取得できるログの種類がサービス内容に依存する点があります。
ディスクイメージの取得が行えない場合には、ホスティングサービス上で与えられた権限の範囲で取得可能な全ファイルの取得を行います。
参考までに主なホスティングサーバの種類とroot権限の有無とログの取得可否についてデータをまとめました(root権限ありの場合はディスクイメージの取得が可能です)。
ホスティングサーバ別のroot権限の有無とログの取得可否リスト
| レンタルサーバ (共有サーバ) | レンタルサーバ (専用ホスティング) | クラウドサーバ (VPS) | クラウドサーバ (IaaS,VPS) | |
|---|---|---|---|---|
| 特徴 | 1台のサーバを複数のユーザで共有。 SSHやFTPが利用できる場合が多い。 リソースは他のユーザと共有。 | 物理サーバを1台専有して利用するホスティング。 | 物理サーバを仮想化技術により分割し、分割された一部を専用のサーバとして提供。 | 基盤となるインフラの管理は不要で、必要に応じてスケールアップ・ダウンが可能。 近年対応することが多い代表的なサービスとして AWS(EC2)、Azure(Azure Virtual Machines)、 GCP(Compute Engine) がある |
| root権限の有無 | 無 | 有 | 有(※2) | 有 |
| ログ取得に関して | かなりの制限あり、一部のログのみ取得可能。 直近のアクセスログのみ、といった限定的な提供が多い。 | ファイルシステム上にあるログが取得可能。 | ファイルシステム上にあるログが取得可能。 | ファイルシステム上にあるログが取得可能。 加えてサービス上取得している監査ログなどが取得可能な場合が多い。 |
(※2) マネージドVPSを除く。
近年特に利用する組織が多くなってきているAWS(EC2)や(Compute Engine)等のクラウドサービス、その他使用しているサービスによってはディスクイメージの保全が可能です。
なお、AWS EC2インスタンスのディスクイメージの取得方法については過去に公開した弊社ブログ記事AWS EC2 のHDD解析(フォレンジック)を参考にしていただけると幸いです。
4.Linuxサーバで見られる主なログファイル一覧
Linuxのログにはどのようなものがあるか見てみましょう。
基本的には/var/log/配下にログが保存されます。
ただし、ディストリビューションによって配置されるディレクトリ名やログファイル名が異なります。
インシデント対応やフォレンジック調査で参照されることが多い、RHEL系とDebian系Linuxの主要なログを以下の表にまとめました。
調査でよく参照する主要なLinuxログファイル一覧
| ログの種類 | RHEL系(CentOS、Red Hat、Fedora)ログファイルパスまたはログ格納ディレクトリパス | Debian系(Debian、Ubuntu)ログファイルパスまたはログ格納ディレクトリパス | ログの説明 | IRやフォレンジック調査時の観点(一部) |
|---|---|---|---|---|
| システムログ | /var/log/messages | /var/log/syslog | サービスやカーネル含むシステム全体のログ | 不審なサービスの起動状況 |
| 認証ログ | /var/log/secure | /var/log/auth.log | SSHなどのログイン、sudo、認証関係のログ | 不正なログイン、権限昇格 |
| cronログ | /var/log/cron | /var/log/syslog | cronで実行された定期ジョブの履歴 | 不審な定期実行やその日時 |
| 監査ログ | /var/log/audit/audit.log | /var/log/audit/audit.log | システムレベルの監査イベント | 不審な設定変更、不正な操作 |
| アクセスログ | ■Apache /var/log/httpd/access_log ■nginx /var/log/nginx/access.log | ■Apache /var/log/apache2/access.log ■nginx /var/log/nginx/access.log | クライアントからのWebアクセスに関する情報 | Webサーバへの攻撃・侵入原因 |
| エラーログ | ■Apache /var/log/httpd/error_log ■nginx /var/log/nginx/error.log | ■Apache /var/log/apache2/error.log ■nginx /var/log/nginx/error.log | クライアントからのWebアクセスに対してサーバ側で発生したエラーなどの記録 | Webサーバへの攻撃・侵入原因 |
| ログインログアウト履歴 | ■ログイン(成功)・ログアウト履歴 /var/log/wtmp ■失敗したログイン試行履歴 /var/log/btmp ■各ユーザの最終ログイン日時 /var/log/lastlog | 同左 | ログイン・ログアウト周りの記録 | 不審なユーザのログイン日時 |
| journalログ(systemd) (※3) | /var/log/journal/ | /var/log/journal/ または /run/log/journal/ | systemdによる統合型ログ | – |
| ユーザのコマンド履歴 | ~/.bash_history (※4) | ~/.bash_history | 厳密にはログファイルではないが、ユーザごとに記録されるbashシェルのコマンド履歴 | 不審なユーザのコマンド操作(ファイル作成、削除、コピーなど) |
(※3)journalログに監視は、認証ログやシステムログが含まれる統合型のログです。バイナリ形式のため、そのままでは可読できません。
(※4)コマンド履歴を確認したいユーザ名が”test-user”の場合、/home/test-user/.bash_historyが当該ユーザのコマンド履歴になります
Arch Linuxは独自のログシステムを持っています。/var/log/以下などにテキスト形式のログは出力されないため、上記表より割愛しています。
詳細についてはArch Linuxのsystemd/ジャーナルについての公式ページをご参照ください。
また上記表にあるユーザコマンド履歴についてですが、日時情報が記録されるよう設定を変更することを推奨します (デフォルトでは記録されません)。
コマンド実行日時が分かることにより、コマンドの実行者が攻撃者であるか正規ユーザであるかの判別が容易になります。
具体的な設定方法として、永続的にコマンド履歴に日時情報が記録されるように「/etc/bash.bashrc」を編集し、以下のいずれかの行を追記してください。
【yyyy-mm-dd hh:mm:ssで日時情報を記録したい場合】
export HISTTIMEFORMAT=”%F %T “
【yyyy/mm/dd hh:mm:ssで日時情報を記録したい場合】
export HISTTIMEFORMAT=”%Y/%m/%d %H:%M:%S “
“source ~/.bashrc”を実行することで設定を即時に反映できます。
Linuxの主要なログファイルを読む上での注意点
紹介したログファイルはほとんどがテキストファイルとして保存されているため、”cat”,”less”,”tail”コマンドで確認することが可能です(gz形式にアーカイブされたログファイルをそのまま読む場合は、”zcat”コマンドで確認可能です)。
注意事項としては、大きなサイズのログファイルをそのまま catコマンド で表示すると、サーバがフリーズしたり、 SSH セッションが切断されてしまうことがあります。
そのため、catコマンドで大きなサイズのログを確認する際は 、grep などでフィルタリングし必要な情報だけを表示することが推奨されます。
なお、一部のログはバイナリ形式などの特殊フォーマットで保存されているため、そのままでは確認することが不可能です。
そのままでは読めないログファイルとその確認方法の一部を以下の表にまとめました。
調査でよく参照する主要なLinux特殊ログファイル一覧
| ログの場所 | ログの種類 | 確認コマンド |
|---|---|---|
| /var/log/wtmp | ログイン(成功)・ログアウト履歴 | last -f /mnt/backup/var/log/wtmp |
| /var/log/btmp | 失敗したログイン試行の履歴 | lastb -f /mnt/backup/var/log/btmp |
| /var/log/journal/ | journalログ(systemd) | journalctl –directory=/mnt/backup/var/log/journal |
上記表の確認コマンドは各種ログを“/mnt/backup/”にコピー(保全)し確認することが前提でのコマンド例になります。
5.Linuxの主要なログファイルの解析方法について
解析に入る前に(超重要)
ログファイルの解析に入る前に、どのタイムゾーンで記録されているログなのかを必ず確認してください。
外部のネットワークログと突き合わせる際に、もとにしているタイムゾーンがずれていると調査結果が間違ったものになってしまいます。(例:ログに記載されている日時がUTCであるのか、JSTであるのかなど)
ログファイルの解析方法
ログファイルの解析にはログフォーマットだけではなくログが記録される経緯(理由・タイミング)についても知見が必要になります。
例えばアクセスログであればHTTPプロトコルに対する理解がなければ、ログフォーマットを把握していたとしてもログの内容を正確に把握することは難しいでしょう。
インシデント対応においては突然ログ解析が必要になることもあり、そのような情報を収集している余裕がないことも多いため、事前に準備したい方は有償のログ解析講座を受講することを検討してください。
なお、ほとんどがOSSで構成されているLinuxのためか、各種ログに関する公式のドキュメントやmanページがほぼあります。 すべて紹介するのはここでは文量的に無理ですが、例えばApacheのアクセスログであればApache公式サイトのログに関するページにログフォーマットに関する説明があります。
では公式ドキュメントをもとに以下のアクセスログを見てみましょう
※以下のアクセスログは説明用サンプルとして作成したものです。実際とは異なる場合があります
198.51.100.1 - - [08/Apr/2025:12:12:12 +0900]
GET /player_api HTTP/1.1 200 999
https://news.google.com/ Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36公式ドキュメントから上記Apacheログ(アクセスログ)は次のように解釈することができます。
IPアドレス「198.51.100.1」のクライアントが2025年4月8日12時12分12秒(日本時間)にHTTP/1.1で /player_api に対してGETリクエストを送っていることがわかります。 さらに、サーバはステータスコード200で999バイトのレスポンスボディを返し、アクセス元はhttps://news.google.com/ 上で何らかの記事を見ている最中にYouTubeのAPIを呼び出したと考えられます。 アクセス元のUser-AgentはWindows 10 64bit 上の ChromeというWebブラウザだったことを示しています。
では順を追って詳細に見ていきましょう。
アクセスログ1行目のログ解説
| 1行目のログ内容 | ログに記録される内容 | 解析結果 |
| 198.51.100.1 | サーバへリクエストをしたクライアント (リモートホスト) の IP アドレスが記録される項目。 | クライアント の IP アドレスが198.51.100.1だということがわかります。 |
| – | RFC 1413 のクライアントの アイデンティティが記録される項目。 | 記録なし (※5),(※6) |
| – | HTTP 認証を用いたリクエストユーザ のID が記録される項目。 | このアクセスでは認証なしのため情報がないと考えられます。 |
(※5)ほとんどの環境で無効化されているため、このフィールドに情報が入ることはほとんどないと思います。公式のドキュメント内でも「この情報はあまり信用することができず、 しっかりと管理された内部ネットワークを除いては使うべきではありません」とあります。
(※6)”-”(ハイフン)は要求された情報が手に入らなかったということを 意味します。
アクセスログ2行目のログ解説
| 2行目のログ内容 | ログに記録される内容 | 解析結果 |
| GET /player_api HTTP/1.1 | クライアントからのリクエストが「HTTPメソッド、URL、クライアント使用プロトコル」の順で記録される項目。 | 以下のように解釈できます。 GET:リソースの取得を意味するHTTPメソッド /player_api:アクセス対象のURLパス、YouTubeの動画埋め込み用APIが取得対象リソース HTTP/1.1:クライアントが使用したHTTPプロトコルのバージョン |
| 200 | サーバがクライアントに送り返すステータスコードが記録される項目。 | ステータスコードは200でリクエストが正常に処理され、リソースがクライアントに返されたことがわかります。(※7) |
| 999 | クライアントに返したHTTPヘッダー部分を除いたHTTPレスポンスボディのサイズが記録される項目。 (※8) | リクエストに対しては999バイトのコンテンツを返したことがわかります。 |
(※7)その他のステータスコード例はMDNのサイトを参照してください。
https://developer.mozilla.org/ja/docs/Web/HTTP/Reference/Status
(※8)クライアントに送信されたオブジェクトの応答ヘッダを除いたサイズを表しますと公式ドキュメントでは記載されていますがわかりづらいので、ここだけオリジナルの記載にしました。
アクセスログ3行目のログ解説
| 3行目のログ内容 | ログに記録される内容 | 解析結果 |
| https://news.google.com/ | リファラと呼ばれるクライアントが報告してくる参照元のサイトのURLが記録される項目。 | Google社のニュースサイト「news.google.com」の記事を見ている中で発生したアクセスと推測できます。 クライアントによって偽装可能な項目です。 |
| Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36 | クライアントのブラウザの情報が記録される項目。 | Windows 10 の64bit環境でGoogle Chromeを使っていたクライアントということがわかります。 クライアントによって偽装可能な項目です。 |
6.実際の調査手順
では実際にGMOイエラエのエンジニアがどのようにログを調査しているかの一部を紹介したいと思います。
今回は、ログ解析の章で取り扱ったアクセスログで具体的な調査手順の一例を紹介します。
1.アクセスログの抽出
2.アクセスログをログ解析ツールへ取り込む
3.取り込んだアクセスログの調査を実施
1.アクセスログの抽出
調査対象サーバを保全し作成したディスクイメージから解析するアクセスログを抽出します。
ディスクイメージが作成できない場合は、調査対象となるアクセスログが保存されているサーバからアクセスログを外部媒体にコピーします。
調査対象サーバを保全(ディスクイメージの取得、アクセスログの外部媒体へのコピー)せずにサーバ上でgrepなどのコマンドを用いて直接アクセスログを調査することも可能ですが、インシデント対応の観点では推奨できません。
これはログローテートにより調査対象のログが削除されるリスクやサーバを直接操作することにより他の証跡が変更されてしまう可能性があるためです。
2.アクセスログをログ解析ツールに取り込む
インシデント対応において調査期間が長くなるほど調査対象のログサイズも膨大になっていきます。
それらのログを人力で解析することは物理的に限界があるため、実際の調査ではログの正規化や検索、集計を行うログ解析ツールを利用しています。
ログ解析ツールにログを取込み、解析を行う上で重要になるのがログの正規化です。
ここでの正規化とは、様々な形式やフォーマットで記録されたログデータを共通の構造に変換する処理を言います。タイムスタンプやログフィールドなどを適切に変換することで、ログ解析ツールでの効率的な分析が実現できます。
ログ解析ツール(プラットフォーム)としてお勧めなのが、ELKです。 ELKとは、 Elastic社がログを収集・検索・可視化するための3つのツール(Elasticsearch、Logstash、Kibana)を組み合わせたログ解析プラットフォームです。
サイバーセキュリティ教育・トレーニング機関SANS Instituteのセキュリティトレーニングでも利用されているELKをベースに開発されたログ分析用プラットフォーム「SOF-ELK」が初心者にはおすすめです 。
SOF-ELKについては本家の公式ドキュメントがとても詳しくわかりやすいので、そちらの参照を推奨しますが、使用方法を少しだけまとめたので参考程度に紹介します。
SOF-ELK公式リポジトリの構成を使って自身で構築することも可能ですが、構築が手間だと感じる方や、すぐ手軽にSOF-ELKを使ってみたいという方向けにすでに環境が構築された仮想環境バージョンが公開されています。
以下では仮想環境バージョンでの使用方法について紹介します。
2-1.SOF-ELKの起動
SOF-ELKの公式ドキュメントをもとにSOF-ELKの構築、起動します。
本記事ではVMware Workstation Pro上に構築したSOF-ELKをホストオンリーネットワークで接続している状態を想定しています。
2-2.SOF-ELKへ解析対象アクセスログを投入
仮想環境内の /logstash/httpd/ディレクトリ配下にアクセスログをコピーします。
上記はアクセスログ投入用のディレクトリになります。
その他にMicrosoft365のログ投入用ディレクトリ「/logstash/microsoft365/」やAWS CloudTrail投入用のディレクトリ「/logstash/aws/」などがあります。
注意点としてログファイルは数ファイル(個人的な感覚として3~9ファイルくらい)に分けてディレクトリに配置してください。
またSOF-ELKの公式サイトでも注意事項として書かれていますが、一度に多数のファイル(数千以上)を読み込むと、システムに過負荷がかかり取り込みに漏れが発生する可能性があります。
2-3.Kibanaへのアクセス
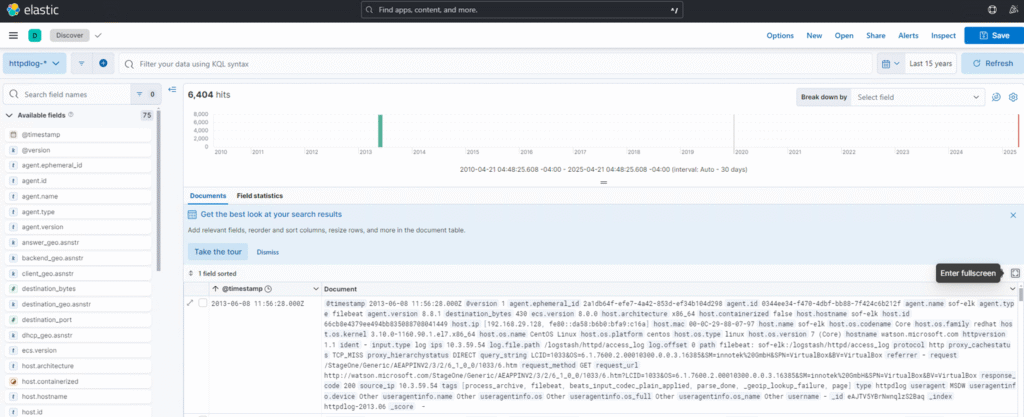
ホストOS(仮想環境を実行しているPC)のWebブラウザから「http://:5601」にアクセスします。
Kibanaへアクセスできたら

①プルダウンメニューを選択
②「Discover」を選択
③Data Viewsから「httpdlog-」を選択すると以下のように取り込んだログを閲覧することができます。
これで解析の準備は整いました。
3.取り込んだアクセスログの調査を実施
実際のインシデント対応では、状況に応じて具体的なフィルターを設定して分析を進めますが、今回は汎用的な調査観点の一例をまとめます。
・送信元IPアドレスを集計しIPレピュテーションを行う
・User-Agentの一覧から不審なものを特定する
・脆弱性の悪用を試みる攻撃リクエストを抜粋する
・非公開にしているコンテンツ・サービスへのアクセスを特定する
・管理系ページへの不審なアクセス
調査するインシデントの種類により他にも様々な観点がありますが、膨大な文字量が必要となるため今回は割愛します。
もし、自身の組織が保管しているログに対してどのような調査が行えるのか確認したい場合には、他の組織で発生したインシデントを参考に訓練や振り返りを行うことが考えられます。
近年ではLLMを活用してシナリオ作成や対応観点を検討するのも、一つの有効な方法として考えられます。
【参考】Linuxログの調査方法の種類について
| 調査方法 | 説明 |
|---|---|
| 文字列検索 | 正規表現などを駆使し目的の文字列の行だけ抽出したい場合や行数が少ないプレーンテキストのログファイルに対して有用です。 使うコマンドとしては、less や cat、grep などがあります。 |
| フォレンジック調査ツールの利用 | ログ解析のみを行う場合はあまりお勧めできません。 ただし、ディスクイメージの削除領域(未使用領域、空き領域)からログの断片を抽出する際はとても有用です(フォレンジック調査する場合は必須作業)。 懸念点としては、機能・性能が優れているとされるものは有料で高額なものが多いです。 |
| ログ解析ツールの利用 | ログ解析ツールにより、可読しやすい形にし調査を実施します。 特にアクセスログなど、膨大な行数なデータに対しては特に有用です。 本ブログでも挙げたオープンソースのELK、有料で有名なものでSplunkなどがあります。 |
実際の調査では、フォレンジックツールによって未使用領域などから抽出したログの断片をログ解析ツールに取り込み調査、または正規表現によって必要な行だけ抽出するなど、複合的にさまざまなツールや調査手法を使う場合が多いです。
おわりに
ログそのものに関する基本的な考え方からLinuxで取得すべきログや期間、調査の際見るべきログなど紹介させていただきました。
ブログという形態上、インシデントのサンプルログを使っての解説までできなかったので次回そのあたりを書ければと思っています。
フォレンジック調査・IRの知見をもとに、今後も情報を発信していければと思います。
ご精読いただきありがとうございました。

