![]()

IERAE DAYSトークセッションレポート 「イエラエが、今、SOCサービスを始める意義」
2023年12月7日(木)に開催された「IERAE DAYS」。その中で行われたセッションを対話形式でお届けします。2回目は「イエラエが、今、SOCサービスを始める意義」です。2023年春よりGMOインターネットグループ向けに提供を開始し、2024年1月「GMOイエラエSOC 用賀」の開設を皮切りに本格的に動き出したSOCサービス事業。IERAE DAYSではGMOサイバーセキュリティ byイエラエならではのSOCサービスとは何かを語らせていただきました。

スピーカーのご紹介

阿部 慎司
大手電気通信事業者でのSOC責任者を経て、GMOイエラエにてSOCイノベーション事業を立ち上げ。日本セキュリティオペレーション事業者協議会(ISOG-J)副代表も務め、ISOG-J「セキュリティ対応組織の教科書」やITU-T国際標準勧告「X.1060」を執筆。その他、日本SOCアナリスト情報共有会(SOCYETI)主宰、IPA専門委員など、幅広く活動。CISSP。

中里 佳浩
電気通信事業者でホスティングおよび自社クラウドサービスのインフラ運用業務に従事。その後SOCサービスの立ち上げを経験し、2022年から現職。現在はSOC業務およびSOC基盤の開発・運用業務を行なっている。

相原 遼
電気通信事業者でNOCやクラウドサービスなどのセキュリティサービス立ち上げを経て2023年から現職。現職ではSOC業務をしつつ、クラウドサービスを活用したSOC基盤を開発および運用を行っている。

髙橋 大喜
営業、フォレンジック調査エンジニア、CSIRTを経て現職。現職ではCSIRT構築支援やコンサルティングを提供している。得意分野は企業のセキュリティガバナンス。
「攻め」から「守り」へ GMOサイバーセキュリティbyイエラエの新たなステージ
阿部:改めまして阿部と申します。私はSOCイノベーション事業部の部長であり、日本セキュリティオペレーション事業者協議会(ISOG-J)副代表でもあります。SOCに関しては10年以上携わっております。GMOサイバーセキュリティbyイエラエには約2年前に入社しました。当社をご存知の方はサイバーセキュリティの分野の中でもペネトレーションテストなど「攻め」の技術に特化した会社というイメージをお持ちの方も多いと思います。では何のためにサイバー攻撃の技術を磨いているのか。それはお客様をお守りしたいからです。
当社は2020年にインシデントレスポンス支援とフォレンジック調査、お客様のCSIRTに教育やセキュリティコンサルティングを行う「ディフェンシブセキュリティ部」を新設し、その後2022年にSOCイノベーション事業部を新設しました。これにより日ごろのセキュリティの運用からインシデント対応までお客様をサポートする体制がようやく整いました。
「SOCサービスをやっている会社なんて昔からいっぱいあるのに、なぜ今更GMOサイバーセキュリティ byイエラエがはじめるのか」そう思われた方も多いと思います。先ほど述べたように当社はもともと脆弱性診断の対応実績数やペネトレーションテストでの圧倒的な侵入成功率や0dayの脆弱性の発見実績を誇る「攻め」の技術に特化したセキュリティ企業です。攻めの目線というのは裏を返すとその対象の弱点をよく知っているということになります。弱点を知り、弱点を補う。弱点を補う守りの技術としてSOCサービスを立ち上げました。

合言葉は「見直す・見守る・身を守る・みんなで守る」
阿部:当社のSOCサービスは「見直す(改善)・見守る(監視)・身を守る(防御)・みんなで守る(支援)」の4つの観点でお届けします。SOCのイメージでいうと「監視」「防御」はわかりやすいですよね。ログを集めて、アラートを検知したら例えば悪性のトラフィックを遮断するとか、エンドポイントでマルウェアなどのコンピュータウイルスが動いていれば駆除するとか、この辺りはSOCとして当たり前ですよね。
繰り返しになりますがSOCサービスは昔からあるものです。規模の大きい企業であれば何らかの形でアウトソースしたり、MSSPのSOCサービスを利用されたり、あるいはSOCサービスを提供している会社の専門家が自社に常駐する形でセキュリティ運用を行うなど、何かしらSOCに関わったことがあると思います。その中で当社がSOCを提供するとしても、もうすでにお願いしている会社があることの方が確立としては圧倒的に高いだろうと思っています。
しかし、サイバー攻撃が巧妙化する中「今の運用体制で十分なのか」を一度考えていただきたいのです。これが「見直す(改善)」という観点です。
SOCサービス自体が定着しているからこそ「どうせどこのSOCも同じだ」という諦めを内心抱いている方も多いのではないかと思います。SOCに携わる人間としてはそういった風潮はなくしていきたい、改善していきたいと思います。
時代の流れの変化として、スタートアップ企業などエンジニア中心にIT技術で戦う企業が増えました。自社サービスとして大規模なWebサービスを構築する際に設計開発段階からある程度セキュリティの意識をもって取り組まれるお客様が増えているのを日々の業務の中でも感じます。あるいは大企業のお客様の中でSOCをアウトソースしているけれど、自分たちが求めるレベルまで高めるには任せきりではいけないという意識を持たれるお客様も増えています。お客様のお悩みとして「今の運用体制でいいのかな」「ログの取り方って今の方法で十分なのだろうか」「アラートが上がるように設定しているけど、これは意味のあるアラートなのだろうか」など色々とあると思います。
「セキュリティ機器をとりあえず入れたけど、高度な攻撃にも対応できるのかな」というお客様や「マルウェアをもっと早く封じ込められるようにしたい」「セキュリティ機器の検知ルールが自社システムの特性に合っているのか不安がある」というお客様もいると思います。
運用上困ったときに頼れる専門家に相談したい、自組織の中でSOCのような動きができる人材を育てる手伝いが欲しい、そういったお客様のニーズも今後増加してくるでしょう。そこで私たちは「みんなで守る」を合言葉にお客様をサポートさせていただきます。
SOCサービスにおける二つの大きな課題
阿部:色々と課題を上げましたが、本日は2点に絞ってアプローチをご紹介したいと思います。1点目はセキュリティ製品の能力への依存度が高すぎるという問題、2点目はSOCサービス同士の断絶感というお話です。
セキュリティ製品の能力への依存度が高すぎるというのは、セキュリティ製品を導入したら意図した通り検知・遮断ができるか確認する必要があるということ。セキュリティ製品は入れたら終わりではないのです。
SOCサービス同士の断絶感とはアンチウィルスソフト、ファイアウォール、IPS(Intrusion Detection System/不正侵入防止システム)、proxy、EDR、クラウド…とSOCで見るべき範囲がどんどん広がっているのに対し、一つのSOCサービスだけではカバーしきれないことです。SOCごとに対象範囲も異なるため、中には複数のSOCにお願いされている企業様もいると思います。このSOC同士の断絶をどう和らげていくのか、どう助けていくのか。SOC事業者としては重い課題として受け止めています。
ここから現在(2023年12月時点)GMOインターネットグループ各社と一部のお客様にご提供しているSOCサービスのメニューについて紹介させていただきます。
まず「防御」について、本来Webサービスを守ろうとすると色んな要素が必要になりますが一番象徴的なのはWAFではないでしょうか。私たちがSOCサービスを開発するにあたって最初に対応したセキュリティ製品はCloudflareのWAFでした。CloudflareのWAFと当社のSOCが連動してお客様のITインフラ環境を守っていくという、構成的には何も珍しくない普通のサービスです。
繰り返しになりますがセキュリティ製品は入れたら終わりではありません。検知・遮断の精度をあげていく必要があります。現状セキュリティ製品に標準セットのシグネチャだけでは十分とは言い難く、検知・遮断をすり抜けて通ってしまう攻撃というのはどのセキュリティ製品であっても必ず存在します。
「独自でシグネチャを作る」大規模な調査結果から出した答え
阿部:実態としてどれくらいの頻度で起こってしまっているのか、GMOインターネットグループの協力を得て3か月に渡り大規模な調査をしました。この調査は検知したイベント(攻撃)に対しWAFの攻撃遮断をすり抜けてWebサーバに到達したイベントがいくつあったかを計測しました。結果としては、ベンダーの標準セットでは防ぎきれない攻撃が万単位で起きているのが明らかとなり、私たちが行き着いた答えは標準セットのシグネチャに加えて自分で防御するためのシグネチャを書くということでそのために「生きた脅威情報」が必要でした。私たちはGMOインターネットグループへ今来ている脅威を観測・分析し、そこからシグネチャを書きました。また最新の脆弱性情報を収集しなるべく攻撃を受ける前から防御できる独自の方式も考えていく。それをサービスとしてお客様に提供することは非常に価値があると思いました。
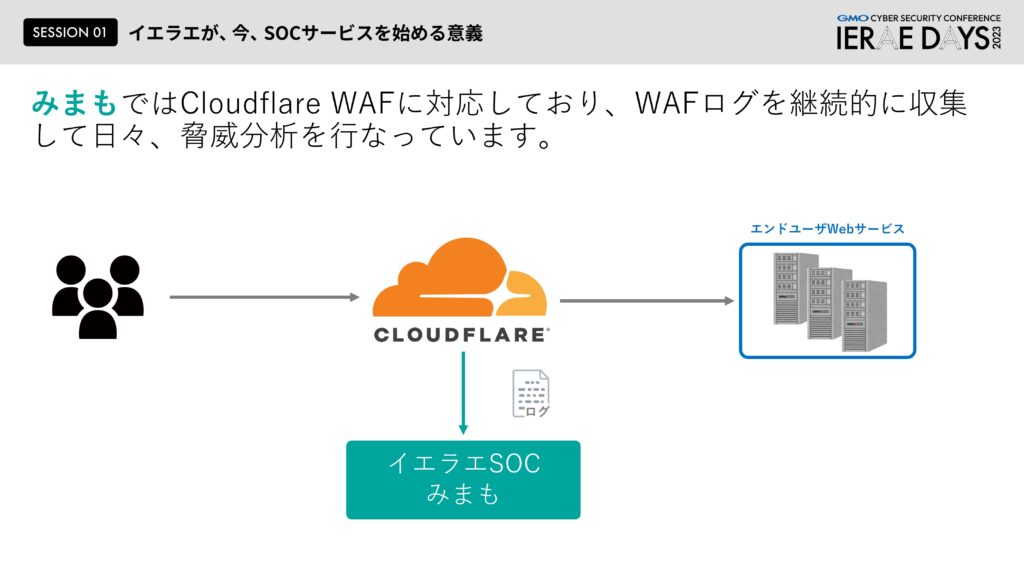
阿部:しかし独自でシグネチャを作るのは意外とハードルが高いです。導入しているセキュリティ製品の検知能力を高めるために新しいシグネチャを追加するのですが、大切なのは「はやさ」と「柔軟性」です。私たちが素早くシグネチャを作ってもセキュリティ製品が適応するのに時間がかかってしまったら意味がない。私たちがいかに素晴らしい検知ロジックを思いついたとしてもセキュリティ製品に入れることができなければ、これも意味がないのです。SOCサービス開発当時、私たちが製品側に求めた「はやさ」と「柔軟性」の条件に一番マッチしたWAFがCloudflareだったため最初にサービスに対応しました。
運用面でも同じく「はやさ」と「柔軟性」が大切です。ここでの運用面とはシグネチャを新しく作る側、つまり私たちのことです。単一のWAFだけに適応するのであれば簡単ですが、それ以外のWAFにも対応するなら作業効率を上げなくてはいけないため仕組みを独自に作りました。
作業効率化のため複数の独自システムを開発
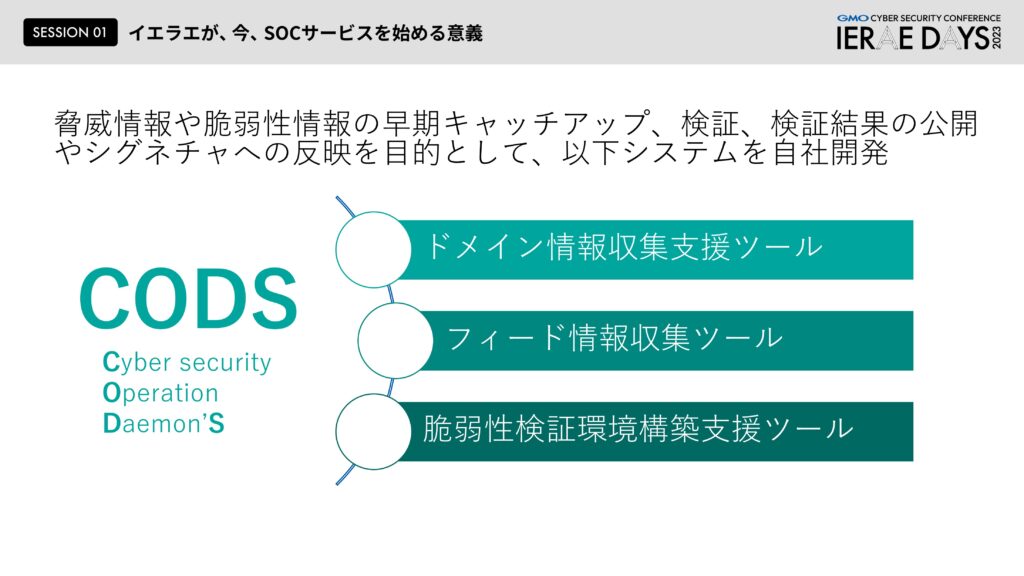
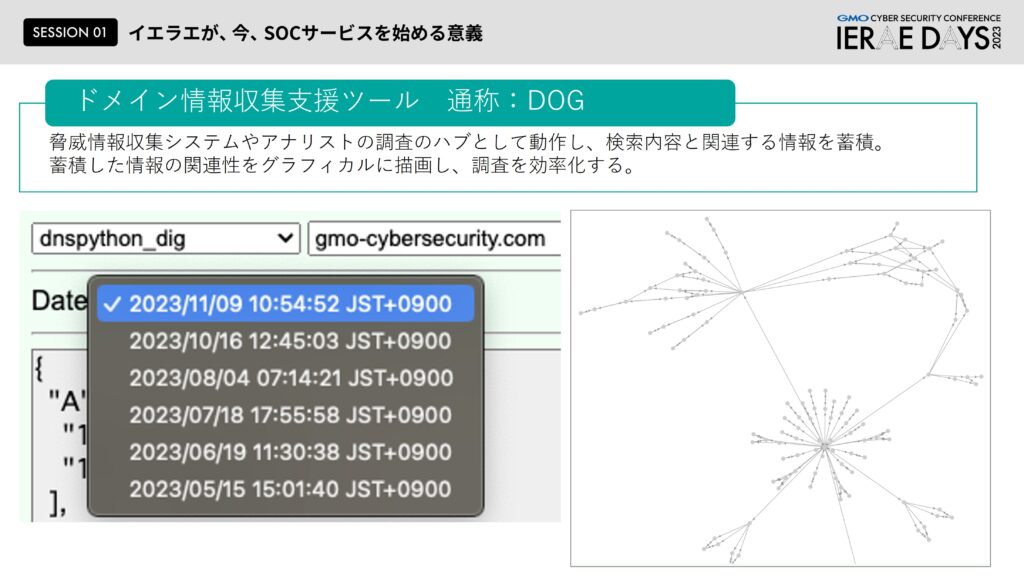
阿部:まず「CODS(Cyber security Operation DaemonS/コッズ)」と名付けたこのシステムは、脅医情報脆弱性情報を早期にキャッチアップするための検証環境の一部であり、プラスそのシグネチャを早く反映させるために、ドメインの情報収集支援ツールやフィード情報収集ツール、脆弱性検証環境を組み込んだものです。またドメイン情報収集支援ツール「DOG」はIPアドレス情報などの情報を集めていくにあたって、アナリストが情報を投入すればするほど色んなIPアドレスやドメイン情報が繋がって全体的な様子を可視化でできるというもので、このシステムはAIも活用していまして、詳細は別途SECCONにてお話させていただくのでそちらにも足を運んでいただければと思います。(SECCONでの登壇レポート:https://developers.gmo.jp/42691/)
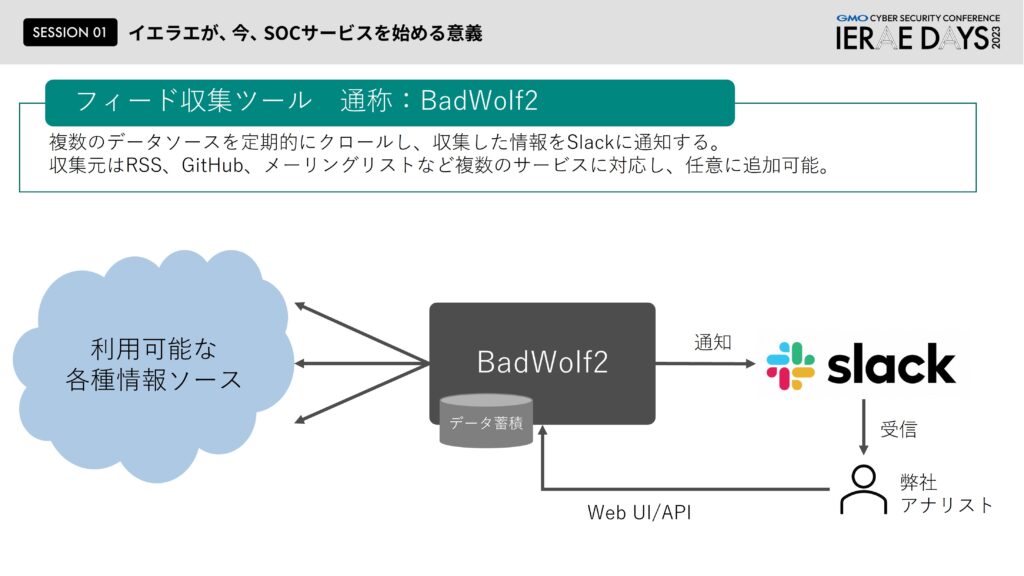
続いて独自のフィード情報収集ツール「BadWolf2」のご紹介ですが、フィードというのはまあ色んな情報があふれています。この情報を集めるのはかなりの労力が必要で、いくらアナリストのアンテナの感度が高くても限界があります。そこで情報収集を自動化するため、上手くデータを蓄積しながら、今話題になっている脆弱性などをピックアップする仕組みを作りより広範囲で情報収集ができるようにしました。
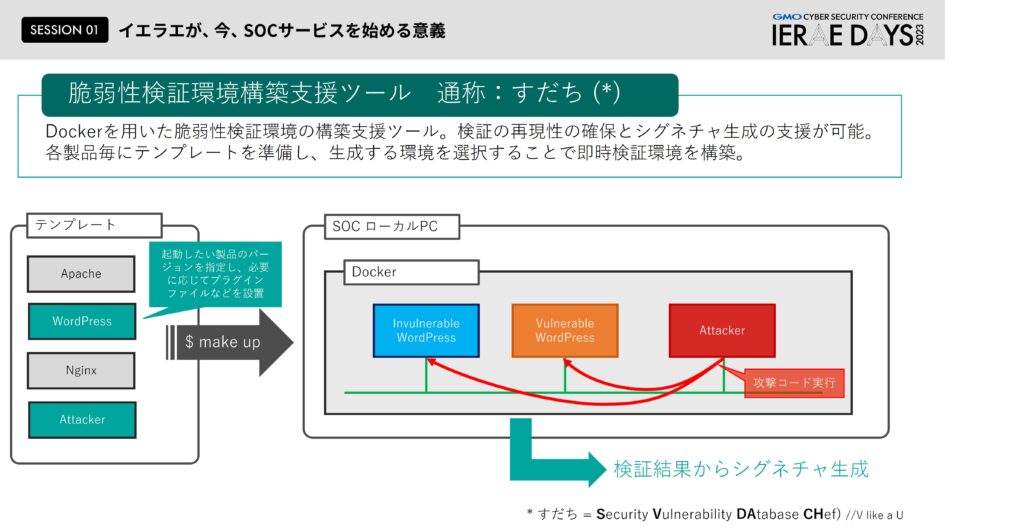
独自の脆弱性検証環境構築支援ツールで攻撃コードの検証とシグネチャの作成を促進
阿部:さらに脆弱性検証環境構築支援ツール「すだち(Security Vulnerability Database Chef /SDACH)」。これはDockerを用いて脆弱性を検証する、要は実際にシグネチャを作成するにあたって攻撃コードを実際に動かしたらどうなるのか、その時通過するパケットはどういった特徴があるのか毎回観測するための仕組みです。攻撃を受ける側としてあえてセキュリティホールがある状態の環境を用意する必要があります。それを各脆弱性やシステムごとにやらないといけないわけですが、この環境構築がすごく大変です。そのためなるべく簡単に作れるようにある程度のテンプレートを用意します。例えばワードプレスのあるバージョンで脆弱性が出てしまったとして、ツールでバージョンを指定するとその環境を再現できるというイメージです。その環境に対して実際に攻撃してみて、その結果からシグネチャをどんどん作成するという仕組みを作っています。
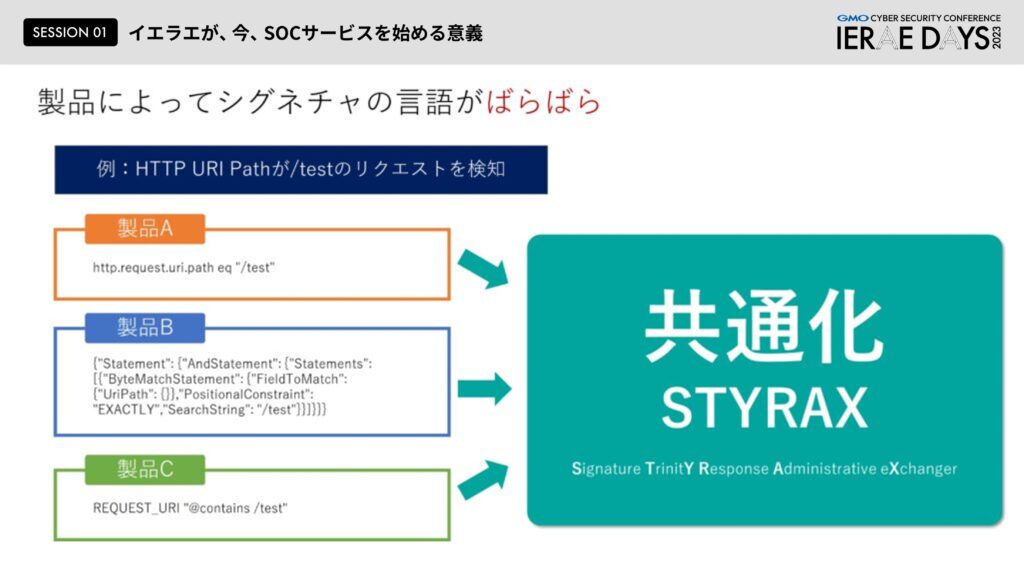
ただ、これから先対象製品が増えた時に、製品A・B・Cとあるとそれぞれシグネチャの書き方もかける範囲も異なります。違う言葉で動いているようなイメージですね。この言語がバラバラなものを一つのロジックを書けば他の製品に適合するように生成AIを活用して自動翻訳する「STYRAX」という仕組みを用意しました。
独自シグネチャを追加することで検知能力が2.3倍に向上
阿部:SOCの中のひとつのメニューである「サイバー予防サービス」では、見きれないぐらいたくさんのサービス群から多種多様な攻撃を集めるのと同時に世の中のフィード情報を収集し、さらに当社のペンテスターが見つけたCVEなどの情報も活用し独自シグネチャを作ってお客様に提供しています。参考値になりますがベンダーシグネチャの数と比較するとすでに約2.3倍のシグネチャ数、つまり検知能力的には2.3倍のロジックが入っている形で我々はSOCサービスを提供しています。また既にCloudflareを導入されているお客様はシグネチャだけのご提供もできます。
またお客様特有のシステムやアプリケーションがあり、それに合わせてしかシグネチャをかけないような場合もあると思います。汎用的なフレームワークを使ったWebサイトならいいのですが、独自で実装していたり、可用性の問題でどうしてもサポートを切れず使い続けないといけなかったりする場合もなくはないですよね。サポートが切れてしまって、公式がパッチは出さないケースですと、この部分だけ疑似的でもパッチを実現したい場合は「サイバー予防カスタム」というメニューでお客様のためだけにシグネチャをご用意することも可能です。
続いて監視寄りの部分、ログ分析のお話に移ります。市販のSIEMを裏で動かすことも最初は考えました。ただそれでは納得ができなかったので結局独自で作りました。その話を相原から説明させていただきます。
独自のログ処理基盤を構築しサービスの提供価格を抑えることに成功
相原:私から「スマートログ分析」と「スマート遮断」またその基盤を支えている「SOLOBAN(Security Operation by Logic Based Analysis Engine/ソロバン)」というシステムについてお話させていただきます。またこれから話す基盤はAWSで作られています。
まずスマートログ分析は何を目的としているサービスかというと、危険なものをより分かりやすく伝えるサービスです。セキュリティログから重要なものを抽出したり、サイバーキルチェーンでどういった攻撃なのか表すようなレポートを出したり、さらにそのレポートをチケット管理システムに起用してお伝えするのが「SOLOBAN」というシステムになります。この「SOLOBAN」についてどういった構成で作られているかについて説明させていただきます。
世の中にはたくさんSIEMがあり、もちろん高機能なものもたくさんあります。ただ実際にそれらを使うと、サービスの提供価格が上がってしまうという問題があります。
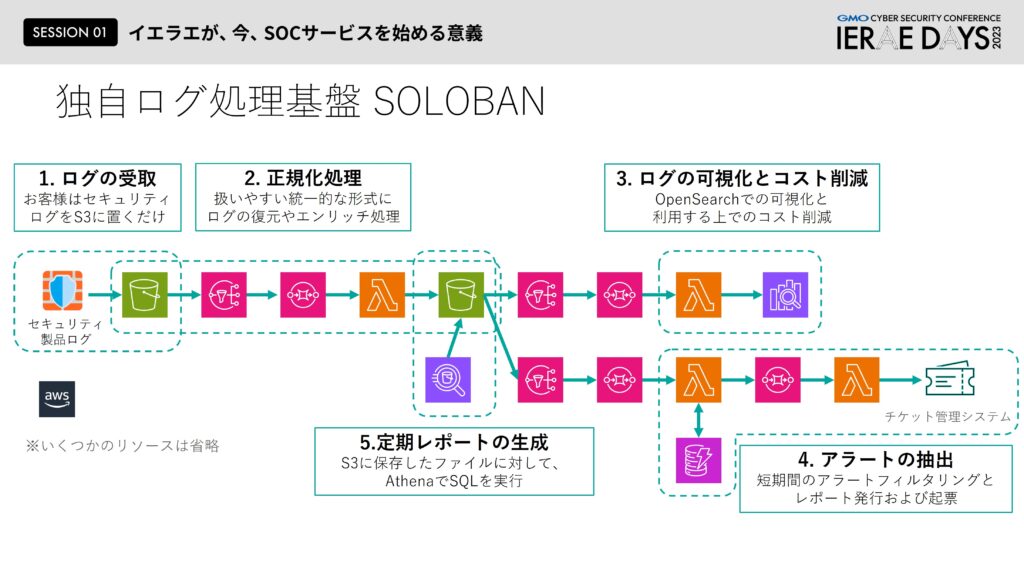
相原:こちらは「SOLOBAN」の概要図です。最初にログの受け取り方法、次に正規化処理、三番目にログの可視化とコスト削減、四番目にアラートの抽出、最後に定期レポートの生成について順を追って説明します。
まずセキュリティログの受け取りについて、ポイントはお客様がS3にログを置くだけにしているところです。ただしCloudflareの場合は少々特殊でCloudflareのWAFは実は部分的に暗号化されています。そのため弊社からお客様にお渡しするマニュアルの中にS3の送り先の情報と暗号の設定方法について記載しております。その設定を参考に、お客様にて作成いただいた秘密鍵を弊社に共有いただきます。このような例外はありつつも、基本はお客様にて対象のログをS3に格納いただければ、あとはログ分析ができる形をとっています。
続いてログの正規化処理ですが、正規化処理の目的自体は一般的なSIEMやログ解析と同じくクエリを実行しやすくするようにすることです。特徴としてはGATEという考えを用いて製品ごとにログのフォーマットが違うものを要素に切り出すためのGATEから、また別の要素を作り出すGATE、いろいろなものを作れるように合成されています。
続いてログの可視化と削減で、正規化されたログはまたLambdaに送られOpenSearch Serviceに挿入されます。このOpenSearch Serviceとは、AWS版のElasticsearchだと思っていただければ大丈夫です。アナリストが定期化されていない分析やビジュアライズとして送信元IPごとのブロックだとか、国ごとにどのような傾向があるかをつかむために使用しています。
ここでポイントが二つあります。一つ目はこの可視化全体の信頼性をAWS全体で、AWSの複数のサービスを使って担保しています。 どういうことかというと、S3にファイルが置かれたというイベントをLambdaが汲み取ってOpenSearch にログを入れるような動作をしているのですが、そのイベントログを録音・録画しておいて、もしもOpenSearch が壊れてしまうなど何かしらの原因で復旧しなければいけない場合にOpenSearchの機能で復旧するのではなく、録音・録画しておいたイベントを再送することでこのログ可視化機能を復旧するという手段を取っています。OpenSearchは費用的価格が高いサービスなのでS3やいわゆるサーバーレスを活用することでコストが抑えられるというメリットがあります。
阿部:サービス価格を抑えるために、あの手この手をエンジニアたちに考えてもらって最終的にこの形に落ち着きました。もしご自身でCSIRTとして基盤を作られていてOpenSearchに依存しているがゆえにコストが嵩むなぁとお悩みの方はこういった発想も是非参考にしていただけると嬉しいです。
相原:この数ヶ月はこのOpenSearchに依存せずいかにコストを削るかが勝負だったところがありますね。
相原:二つ目のポイントはアラート抽出や定期レポートは他のAWSサービスを利用しています。アラート抽出も定期レポートもOpenSearchでもちろんできますが、先述の通りOpenSearchが常に起動していることに期待せずにLambdaやAthenaなど、よりAWSマネージドなサービスを使うことで、常にお客様にサービスを提供できるよう継続性を向上させることを狙っています。 このようにしてOpenSearch自体のスリム化や運用コストの軽減を実現しています。
アラートの抽出をOpenSearchでやらない理由の一つとしては期間の短縮や、ニアリアルタイムでのアラート処理の問題で、現在特定ルールのカウントアップで、DynamoDBとLambdaが連携しながら重要なアラートを抜き出す作業をしています。
実際には複数のLambdaが動いていて、重要なものを抽出し通知しなければいけないものは、後続のLambdaに送られて必要なものをPDF化してさらにチケット管理システムに起票と添付を行うという作業です。OpenSearchを使わずサーバーレスで合成できるので管理負荷も抑えられる上に可用性も向上しています。
また定期レポートの生成では、実は正規化処理中にアウトプットをS3においているのですがその形式をParquetというデータ形式にしています。ParquetとはCSVが行指向のデータであるのに対して、列指向のデータ形式を持つものでそれに対してAthenaというAWS機能のサービスでSQLを実行しています。定期レポートや定期で実行しなければいけない長期間のログインに対するクエリを行っています。
Parquetデータ形式をなぜ利用しているかについてですが、Athenはデータスキャンドクッキーになります。どういうことかというと、methodとカウントリーとIPアドレスと3つデータがあった時に、カウントリーだけ計上したい時は他の2つが余分になってしまいますよね。 CSVだと全て読みだしてしまいますがParquetだとこの縦一列だけを読みだすことができて、データスキャン量が抑えられます。単純なことですが、これらの積み重ねでコストを削減しています。
またスマート遮断についてお話しますと、スマート遮断は「伝えた後にアクションをする」というサービスです。レポートが出てきた時に、例えばEDRのアクションとしてその感染端末を即座に論理隔離するようなアクションを加えたものです。
阿部:WAFも含めてですが、検知時間と送信元IPアドレス、宛先のIPアドレスの検知名と…そのログから何を読み取ればいいのか?が皆さん困るところだと思います。スマートログ分析を行うと、当然いらないログ(意味のないログ)もたくさんあります。狼少年のように実際には危険ではないのにアラートが挙がっているケースもたくさんあります。それらを排除すると本当に読み解くべきはあるログの一行かもしれません。
我々はSOLOBANを使って攻撃の進行度を可視化し、その進行度に合わせてお客様に状況をお伝えしています。また危険度に合わせて色分けをして、レポートを見ればどんな「温度感」で受け取るべき内容なのか感覚的に一目でわかるようにしています。もちろん推奨対策として簡単にできる対策は書かせていただきます。
加えてスマート遮断を追加されると、例えばEDRであれば論理隔離まで対応したり、WAFであればシグネチャやIT単位でブロックしたりなど状況に合わせて対応していきます。
しかし何か起きてしまうときは起きるものなので、やはりその後の対応も重要です。 ここから先は仮に「やられてしまった」時のお話をさせていただきます。
組織のサイバーセキュリティにとって極めて重要な「ガバナンス」
高橋:ここから先は私からお話します。私はディフェンシブセキュリティ部セキュリティスタッフ課・課長の高橋と申します。業務としてはセキュリティコンサルタントやCSIRT/PSIRTの構築支援などを行っています。
本日は実際に発生してしまったサイバーセキュリティ事故に対して、サイバー攻撃の被害を検知し収束させるまでの一連のプロセスについて重点的に話そうと思っています。また企業ガバナンスの整備についても触れます。一部の人には耳の痛いところもあるかもしれないですが、大切なことですのでお聞きいただけると幸いです。
これは私が提唱していることなのですが、事故対応はガバナンスの集大成であると考えております。具体的にどういうことかと言いますと、例えばSOCを利用する・しないの判断、どこを監視し、どういうタイミングでレポートするかという「決め事」が重要です。
実際ガバナンスとは何か定義を考えてみました。経産省の情報セキュリティガバナンスの概念を引用し、今回の講演の中では①決め事があり②その決め事が守られていて③決め事が守られている状態を観測できる。この三つが揃った状態をガバナンスと定義してみようと思います。

高橋:では実際それぞれの例について、まず①決め事がありというところ。ここはセキュリティポリシーやガイドラインルール、手順書などが該当します。②の決め事が守られているかは、施策レベルまで落ちているか、チェックリスト化できているか、チェックリストではどういう基準であればイエスノーが付けられるのかと、それを監査しているかを指します。③の決め事が守られていることを観測することとは、監査の結果、監査自体のプロセス、ルールや施策を決定するときのプロセス、意思決定などです。要は結果に至るまでの過程を可視化しましょうというところです。
ではガバナンスを事故対応に当てはめたらどうなるかをまとめてみました。
実際に事故が起こった時に備えてどういう準備が必要か。まず事前に誰が事故に対応するのか、どういった方針・計画で対応を進めるのか、資産の重要度など、企業で整えておくべき事項を洗い出します。そこから具体的な事故対応の担当部門、各担当者の役割、責任範囲や最終的な意思決定者、事故対応手順、資産など情報の一覧化、部門間の連携方法の明確化などを行います。これが決め事になります。
対してその決め事が守られているかは、意思決定プロセスが定まっているか、自社で利用しているサービスはどのようなものがあるか、事故対応で使うツール類のSLAや、外部委託の範囲を正しく認識しているか、またその事故の危険度や優先的に対応すべきか否かの重要度が事前に取り決めた基準に従って判定されているか等が該当します。
さらにその決め事が守られていることを観測するために、事故対応の時の作業の記録をしっかり取ること。事故対応後に自分たちの対応はどのようなものだったか振り返りをすることを、私は強く推奨しています。事故対応の振り返りから学べることはとても多く、やるのとやらないのとでは、組織の成長度に二段階くらいレベルの差が生まれてくると思っています。
事例から見る ガバナンスが「効いていない」状態とは
高橋:ではこれらが満たせていない(ガバナンスが効いていない)とどうなるか、実例を交えてご紹介します。匿名ですが、当社で実際に事故対応支援にあたったお客様のお話です。そのお客様は、ランサムフェアに感染し端末が使えなくなったタイミングで当社にフォレンジック調査をご依頼いただきました。当社での調査の結果、半年前くらいに不正アクセスされた形跡が見つかりました。お客様は当社で調査するまでそんな記録があると把握されておらず、当社のフォレンジック調査員からこういうログありますか?と都度確認し、かき集めたログを見て判明した内容でした。
これはガバナンスが効いているとは言い難い状況です。事前の決め事が無視されてしまい、情報資産の一覧化ができていない、事故対応の方針も決められていません。ではどうすれば良かったのかですが、まずは自社で起こりうるサイバーインシデントを洗い出しておく必要がありました。システム上で起こるインシデントシナリオとそのインシデントシナリオが顕在化した時に、どれくらいビジネス上のリスクになるのかというところですね。
不正アクセスなどの脅威が実現し、例えばどんな情報が漏えいしたら、何が起きてしまったら自社にとって良くない状況なのかを考えて、重大度の定義付けをする必要があります。
インシデントシナリオが洗い出せたら、自社で取得するログを洗い出します。基本的に取得すべきは重要な資産とその周辺です。取得するログの洗い出しが終わったら、次は保管期間を決めます。何年取ればいいですか?何ヶ月取ればいいですか?とよく聞かれるのですが、これは資産の重要度やインシデントの重要度により変わります。また保管期間やエクスポートのルール、改ざん検知がどうなっているかも合わせて確認しましょう。
実際にインシデントが起こりうるか、そのインシデントの調査には何が必要かまで整理できてからインシデント発生時の対応を検討します。これができていれば、先の件のようなことにはならなかったでしょう。
経験を生かす 事故対応後の振り返りの重要性
高橋:さらにその先にどうしたらよいかも少しお話ししようと思います。先ほども申し上げた通り事故対応後に振り返りをするということはとても重要です。この時に対応に当たった担当者の心情というものも加味してください。 担当者が「辛い」と感じたポイントは、改善の余地があります。例えばどこにどんな情報が入っているのかが分からずパニックになって辛かったなら、情報の管理方法見直す余地があります。
事故対応というのは事前にできることをやっておかないと、とてもまともに対応することはできません。被害が拡大する、対応が後手に回る、対応が遅れたばかりに風評被害に発生することもあります。また決め事は出来るだけ具体的かつ、実現可能なものにする。そうでないと事故対応が終わらなくなってしまいます。そして適任者を任命し必要な人数をアサインするのはマネジメントする立場の方や経営陣の責任です。本来サイバーセキュリティ対策というものは、経営責任のひとつなのです。
決め事をどう定めていくかわからなければ、現状把握として自社で取り扱っている情報資産、その情報資産を従業員の人はどういう使い方をしているのか、どういう経路でアクセスしているのかなどを、いろいろなものを可視化してみてください。可視化するだけ見えてくる課題もあります。ガバナンス面やCSIRT/PSIRTの対応構築に関して何か困りごとがあればいつでもサポートさせていただきますので、お気軽にご相談ください。事故対応マニュアルの作成など特定の課題のみに関するご支援も可能です。

「セカンドオピニオン」でSOCサービス同士の壁を壊す
阿部:今後はSOCから事故対応部隊にスムーズに連携しお客様をトータルでサポートしてまいります。最後にご案内したいのが「セカンドオピニオン」と「セキュリティ運用評価/改善アドバイザリー」です。
SOCで監視をしていると「あれ、これどうなんだろうなぁ」と判断が付かない状況に陥ることもあると思います。本当にどれぐらい危ないと考えるべきか、実際どこまで攻撃が到達しているかわからないし、インシデント対応の予算取るほどのことなのか、迷ったときに「セカンドオピニオン」をご検討ください。
「セカンドオピニオン」はお客様からご提供いただいたログをアナリストが分析し、今どのような状況であるか考えられる可能性をレポートします。インシデントハンドルへ速やかに繋げることを目的に初期の対策の助言から、必要に応じてインシデント対応に誘導したり、当社のインシデント対応支援チームと連携したりします。またセカンドオピニオンという名前通りお客様がすでに導入している他社のSOCサービスからのアウトプットも分析対象にすることができます。SOCサービス同士の断絶を解決したいという思いがありますので、対象は限定していません。またセカンドオピニオンは単品だけでご契約も可能です。心配な時だけ相談したい、この範囲だけ対応お願いというのも、もちろんOKです。
疑似的なインシデント対応を経験することで見える課題と改善方法
阿部:「セキュリティ運用評価」というメニューもご用意していますが、これはペネトレーションテストと連動するサービスで、ペネトレーションテストにおける攻撃(疑似攻撃)が成功に至るまでの防御側の姿勢として、ログは取れていたか、そのログからちゃんと危ないものを検知しアラートがでていたか、さらにアラートを受け取って、きちんと対応まで結びついていたか、この三つの観点で運用を評価します。
ペネトレーションテストでは偵察をし、マルウェアを実行し、横展開し、アカウントの権限を昇格し、さらに横展開し、最後に何らかのゴールに到達する…という一連の流れがありますが、この中で皆さんがどこのどの対応を苦手としていたのか?攻撃者から見た時の一連の流れにおいて、どこに大きな穴があったかを、ログ、アラート、対応の三点から見ていきます。
「セキュリティ運用体制構築改善アドバイザリー」は、例えばセキュリティ運用評価をした際にそもそもログが全然取れていないことが大きな課題として上がったとします。そのような問題が起きてしまった背景に、ログを管理するポリシーが存在せず、また予算も確保しておらず対応のしようがなかったという状況だとしたら、これは現場で対応するエンジニア個個人が頑張ってどうにかなる話ではないですよね。あるいはアラートも出ていたのに、CSIRTが他の業務で手一杯になって確認が遅れてしまったのであれば対応リソースの課題ということもあります。
こういった技術で解決できない問題、組織的に取り組まないと解決できない問題というのもたくさんあります。そういった場合にはセキュリティ運用体制構築改善アドバイザーという形で、より長期的な視野、俯瞰的な視点での課題出しをして改善していくお手伝いをさせていただくサービスもございます。
まとめると、ペネトレーションスタート地点として考えて、ペネトレーションテストで報告される個々の問題に対処しましょう。次に運用管理として、ログが取れていたか、アラートが出ていたか、対応ができたかを振り返り、出来なかったあるいはできたけど苦労したという点はどこか可視化して、改善していく方法を一緒に考えましょう。それが運用の問題なのか組織の問題なのか切り分けて、組織の問題なら必要に応じて経営層も一員となって改善していきます。技術観点、運用観点、組織観点で人と人通り横串に刺してやることで、初めて会社として組織としてセキュリティレベルを上げていくことができるのです。
SOCサービスは運用という狭い面を見ているように聞こえるかもしれませんが、我々が提供するSOCサービスには全方位でお客様の組織を守りたいという思いが込められております。
また当社のSOCサービスは他社様と協業する形でサービス提供することも可能です。
詳しくはWebサイトまたは担当営業に直接お問い合わせいただければと思いますが、再販という形でももちろん可能ですし、例えば現在SOCサービスを提供されている事業者様であればその事業者様の対象範囲外の部分は私たちが提供するセカンドオピニオンサービスをオプションとして付けていただいてお客様に一緒にご提案するということも可能です。
誰にも分け隔てなくこのSOCサービスを提供し、皆様の会社をそして日本社会を「守りたい」。その気持ちでさらにこのサービスが進化するよう日々研究開発を重ねています。ぜひともSOCサービスをどうぞよろしくお願い致します。本日はありがとうございました。
GMOサイバーセキュリティ byイエラエは、エンジニアが常駐し活用する「第一SOC」と、お客様への集中的なサイバー攻撃などの緊急時にエンジニアが一同に会して防御・分析を行う「第二SOC」の2つのSOC(Security Operation Center)を設置しています。これらのSOCはセキュリティの研究開発や情報発信の拠点としても活用する予定です。サイバーセキュリティ事業は、同社のインターネットインフラ事業との強いシナジーが期待できます。GMOインターネットグループ、GMOサイバーセキュリティ byイエラエは本取り組みを通じて、日本のSOC、サイバーセキュリティの強化に貢献してまいります。
SOC(Security Operation Center)とは?概要や必要性を解説

