![]()

【reversing】 IERAE CTF 2025 公式 Writeup
本記事では2025年6月21日~22日に開催された、IERAE CTF 2025のReversing問題の解法を解説します。
- rev rev rev (warmup)
- rotrotrot (easy)
- Skip Skip Skip 1 (easy)
- Skip Skip Skip 2 (hard)
- AVX-512 (hard)
- GMOPass (extreme)
他のジャンルの解説は以下の記事をご覧ください:
rev rev rev (warmup)
作問者: rama
正解チーム数: 360
概要
提供されているファイルは2種類です。pythonのソースコードと、そのコードの結果です。
flag = open('flag.txt', 'r').read()
x = [ord(c) for c in flag]
x.reverse()
y = [i^0xff for i in x]
z = [~i for i in y]
open('output.txt', 'w').write(str(z))[-246, -131, -204, -199, -159, -203, -201, -207, -199, -159, -204, -158, -155, -205, -211, -206, -201, -206, -205, -211, -158, -159, -207, -202, -211, -199, -206, -155, -206, -211, -204, -200, -200, -200, -203, -208, -159, -199, -133, -187, -191, -174, -187, -183]解法
解法1. 逆から実行する
解法2. LLMに解法を聞く
フラグ: IERAE{9a058884-2e29-61ab-3272-3eb4a9175a94}
rot rot rot (easy)
作問者: n4nu
正解チーム数: 77
概要
配布されたファイルはx86-64のELFとこのプログラムの出力がファイルとして与えられています。ELFファイルを解析し、プログラムの出力から入力を求めるのがこの問題の目標です。以下がELFファイルの処理概要です。
Phase1とPhase2関してはバイナリの処理をもとに同一の処理を行うコードを作成すれば、それに対する復元コードを容易に作成することが可能です。
また、Phase3については入力の先頭4バイトに依存しているため、一見特定が難しそうに思えますがflagのフォーマットは提供されているのでこの情報をもとにseedを特定することで、復号することができます。ただし、flagフォーマットの仮定を置かなかったとしても、seedが32bitであるため総当たりで特定することも可能です。
解法
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
// Bitwise rotations
static inline uint8_t rol8(uint8_t value, int count) {
count &= 7;
return (value << count) | (value >> (8 - count));
}
static inline uint8_t ror8(uint8_t value, int count) {
count &= 7;
return (value >> count) | (value << (8 - count));
}
static inline uint32_t rol32(uint32_t value, int count) {
count &= 31;
return (value << count) | (value >> (32 - count));
}
static inline uint32_t ror32(uint32_t value, int count) {
count &= 31;
return (value >> count) | (value << (32 - count));
}
// rot13 single byte
static inline uint8_t rot13_byte(uint8_t c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M')) return c + 13;
if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z')) return c - 13;
return c;
}
// key generation
uint32_t generate_key(uint32_t x) {
x = (uint32_t)(x * 0xe8601017U);
x ^= rol32(x, 13);
x = (uint32_t)(x * 0x9aa454efU);
x ^= ror32(x, 5);
x = (uint32_t)(x * 0xa94dc8cfU);
x ^= rol32(x, 24);
x = (uint32_t)(x * 0xda41c486U);
x ^= ror32(x, 17);
return x;
}
// decrypt function
void decrypt(const uint8_t *data, uint8_t *out, size_t length, uint32_t seed) {
// step1: XOR
uint32_t key = generate_key(seed);
uint8_t *buf = malloc(length);
for (size_t i = 0; i < length; i++) {
buf[i] = data[i] ^ (uint8_t)(key & 0xFF);
key = generate_key(key);
}
// step2: block rotation
uint8_t *out2 = malloc(length);
int rot_times = 0;
for (size_t j = 0; j < length; j += 8) {
size_t block_size = (length - j >= 8) ? 8 : (length - j);
rot_times = ((rot_times + 3) % 7) + 1;
int r = rot_times % block_size;
for (size_t k = 0; k < block_size; k++) {
size_t src = (k + block_size - r) % block_size;
out2[j + k] = buf[j + src];
}
}
free(buf);
// step3: per-byte rotation + rot13
int rot_amount = 0;
for (size_t i = 0; i < length; i++) {
rot_amount = ((rot_amount + 4) % 7) + 1;
uint8_t c = out2[i];
uint8_t x = (i % 2 == 0) ? ror8(c, rot_amount) : rol8(c, rot_amount);
out[i] = rot13_byte(x);
}
free(out2);
}
// check if all characters of the decrypted text are printable
int is_printable(const uint8_t *data, size_t length) {
for (size_t i = 0; i < length; i++) {
if (data[i] > 0x7E) return 0;
}
return 1;
}
int main(int argc, char **argv) {
if (argc < 2 || argc > 3) {
fprintf(stderr, "Usage: %s <encrypted_file> [seed]\n", argv[0]);
return 1;
}
// read file
FILE *f = fopen(argv[1], "rb");
if (!f) {
perror("fopen");
return 1;
}
fseek(f, 0, SEEK_END);
size_t length = ftell(f);
fseek(f, 0, SEEK_SET);
uint8_t *data = malloc(length);
if (fread(data, 1, length, f) != length) {
perror("fread");
fclose(f);
return 1;
}
fclose(f);
uint8_t *plain = malloc(length + 1);
plain[length] = '\0';
if (argc == 3) {
// if length of argv[2] is fewer than 4, return error
if (strlen(argv[2]) < 4) {
fprintf(stderr, "Error: seed must be 4 bytes long.\n");
free(data);
free(plain);
return 1;
}
// convert argv[2] to uint32_t
uint32_t seed = 0;
for (size_t i = 0; i < 4; i++) {
seed |= ((uint32_t)(unsigned char)argv[2][i]) << (i * 8);
}
decrypt(data, plain, length, seed);
printf("Used seed: 0x%08X\n", seed);
printf("Decrypted text:\n%s\n", plain);
printf("Decrypted text (hex):\n");
for (size_t i = 0; i < length; i++) printf("%02X", plain[i]);
printf("\n");
free(data);
free(plain);
return 0;
}
uint64_t cnt = 0;
// brute force
for (uint8_t a = 0x20; a < 0x7F; a++) {
for (uint8_t b = 0x20; b < 0x7F; b++) {
for (uint8_t c = 0x20; c < 0x7F; c++) {
for (uint8_t d = 0x20; d < 0x7F; d++) {
uint32_t seed = (uint32_t)a | ((uint32_t)b << 8) | ((uint32_t)c << 16) | ((uint32_t)d << 24);
decrypt(data, plain, length, seed);
cnt += 1;
if (cnt % 0x800000 == 0) {
printf("Trying seed %08lx: %08X => ", cnt, seed);
for (size_t i = 0; i < length; i++) {
printf("%02X", plain[i]);
}
printf("\n");
}
uint32_t prefix = 0;
for (size_t i = 0; i < 4; i++) {
prefix |= ((uint32_t)(unsigned char)plain[i]) << (i * 8);
}
if (prefix == seed) {
printf("Found seed bytes: '%c%c%c%c' (0x%02x%02x%02x%02x)\n", a,b,c,d, a,b,c,d);
printf("Decrypted text:\n%s\n", plain);
printf("Decrypted text (hex):\n");
for (size_t i = 0; i < length; i++) {
printf("%02X", plain[i]);
}
printf("\n");
}
}
}
}
}
free(data);
free(plain);
return 1;
}
このプログラムを実行すると、flagが得られます。
IERAE{Rot!Rot!Rot!_91961c2b05ff7eb8b940011210731f298509d87a4c2f33b294322688d931a852}Skip Skip Skip 1 (easy)
作問者: anonymous
正解チーム数: 30
概要
この問題は、ハードウェアにおけるFault Injection攻撃をエミュレーション環境で疑似的に再現し、プレーヤーに攻撃を行わせるものです。
プレーヤーは、サーバー上で動作するプログラムに対し、動作中のタイミングを指定して1命令だけ実行をスキップさせられます。
これを利用してプログラムの中にある秘密のデータ(フラグ)を読み取ることが目的です。
配布ファイルのkernel.binはエミュレーション環境で動作する攻撃対象のプログラムです。
このプログラムを命令スキップ無しで通常通り実行すると、次の出力を得ます。
Welcome to Flag Provider Service!
The flag is ......
*drumroll*
Sorry, it's a secret!
Thank you for using our service!
命令スキップの概要は次の通りです(サーバー接続時のバナーを引用)。
In this challenge, we simulate Fault Injection attack against hardware within an emulation environment.
You can skip a single instruction at a specified timing in a program running on QEMU.
The timing for skipping an instruction is specified using characters output by the program as a temporal trigger point.
This timing is configured using three parameters: Character, Count, and Offset.
Character: A single character that determines when the trigger activates
Count: The number of times the specified character must appear in the output before the trigger fires
Offset: The delay (in nanoseconds) between the trigger firing and the instruction skip
For example, with parameters Character = 0x41, Count = 2, and Offset = 100000, one instruction will be skipped 100,000 nanoseconds after the program outputs the character "A" for the second time.
You can give arbitrary input to the program.
Notes:
* Character output from the program occurs when a STR instruction is executed to address 0x101f1000
* In the QEMU environment, approximately one instruction executes every 1024ns
* The QEMU environment is deterministic: using the same parameters will always fire the trigger at the same timing and skip the same instruction
サーバーへ接続し、適当にタイミングを指定して命令スキップを行うと、次のような返答を得ます。
Enter trigger character (0x00 <= x <= 0xff):
0x0a
Enter trigger count (1 <= x):
2
Enter offset time in ns (0 <= x):
100000
Enter input (hex):
0a
Running the application......
Completed.
Output:
b"Welcome to Flag Provider Service!\r\n\r\nThe flag is ......\r\n*drumroll*\r\nSorry, it's a secret!\r\n\r\nThank you for using our service!\r\n"
Observation log:
[************] Log format: [(Machine time in ns)] (message)
[************] pattern = 0x0a
[************] count = 2
[************] offset = 100000 ns
[************] Loading flag into memory address 0x20000......
[************] Setting a trigger......
[************] Running the target......
[000000016384] ch = 0x57
[000000023552] ch = 0x65
[000000030720] ch = 0x6c
[000000037888] ch = 0x63
[000000046080] ch = 0x6f
......
[000000236544] ch = 0x63
[000000243712] ch = 0x65
[000000250880] ch = 0x21
[000000258048] ch = 0x0a
[003146011648] ch = 0x0a
[003146011648] Trigger fired!
[003146011648] Resuming the target and waiting for the offset time......
[003146011648] ch = 0x0a
[003146018816] ch = 0x54
[003146025984] ch = 0x68
[003146034176] ch = 0x65
[003146041344] ch = 0x20
[003146048512] ch = 0x66
[003146055680] ch = 0x6c
[003146062848] ch = 0x61
[003146070016] ch = 0x67
[003146078208] ch = 0x20
[003146085376] ch = 0x69
[003146092544] ch = 0x73
[003146099712] ch = 0x20
[003146106880] ch = 0x2e
[003146110976] Skipping an instruction......
[003146110976] Resuming the target......
[003146120192] ch = 0x2e
[003146127360] ch = 0x2e
[003146134528] ch = 0x2e
[003146141696] ch = 0x2e
[003146148864] ch = 0x2e
......
このように、各文字の出力タイミングを観察しつつ、命令スキップのタイミングを指定できるようになっています。
これは、マイコンに対するUART出力をトリガーとしたFault Injection攻撃の様子を模擬的に再現したものです。
解法
スキップする命令の特定
プログラムのソースコードは次のようになっています。
main.c:
#include "uart.h"
#define FLAG_SIZE 32
__attribute__((section(".flag"))) volatile char flag[FLAG_SIZE] = "IERAE{DUMMY_FLAG}";
volatile int reveal_flag = 0;
void sleep() {
for (volatile int j = 0; j < 500000; j++) {
asm volatile ("");
}
}
void main(void) {
uart_puts("Welcome to Flag Provider Service!\n");
sleep();
uart_puts("\nThe flag is ......\n");
sleep();
uart_puts("*drumroll*\n");
sleep();
if (reveal_flag) {
uart_puts(flag);
uart_puts("\n");
}
else {
uart_puts("Sorry, it's a secret!\n");
}
uart_puts("\nThank you for using our service!\n");
}
uart.c:
#include "uart.h"
#define UART0_BASE 0x101f1000
#define UART0_DR (*(volatile unsigned int *)(UART0_BASE + 0x00))
#define UART0_FR (*(volatile unsigned int *)(UART0_BASE + 0x18))
void uart_putc(char c) {
while (UART0_FR & (1 << 5));
UART0_DR = c;
}
void uart_puts(const char *str) {
while (*str) {
uart_putc(*str++);
}
}
......
ここではソースコードをそのまま示しましたが、概ね同じ情報がプログラムの解析から得られます。
また、このソースコードではflag変数がダミー値ですが、サーバー上では実際の値が書き込まれます。
この問題ではreveal_flag変数を非ゼロに変化させられればフラグが出力されますが、この変数は常にゼロのため、通常はフラグが出力されることはありません。
ここで命令スキップを利用します。
main関数の機械語は次のようになっており、if (reveal_flag) 行の条件分岐に対応するのは101f4のbeq命令です。
000101c4 <main>:
101c4: e92d4010 push {r4, lr}
101c8: e59f0054 ldr r0, [pc, #84] @ 10224 <main+0x60>
101cc: ebffffa5 bl 10068 <uart_puts>
101d0: e59f0050 ldr r0, [pc, #80] @ 10228 <main+0x64>
101d4: ebffff8c bl 1000c <sleep>
101d8: ebffffa2 bl 10068 <uart_puts>
101dc: e59f0048 ldr r0, [pc, #72] @ 1022c <main+0x68>
101e0: ebffff89 bl 1000c <sleep>
101e4: ebffff9f bl 10068 <uart_puts>
101e8: ebffff87 bl 1000c <sleep>
101ec: e59f303c ldr r3, [pc, #60] @ 10230 <main+0x6c>
101f0: e5933000 ldr r3, [r3]
101f4: e3530000 cmp r3, #0
101f8: 0a000006 beq 10218 <main+0x54>
101fc: e59f0030 ldr r0, [pc, #48] @ 10234 <main+0x70>
10200: ebffff98 bl 10068 <uart_puts>
10204: e59f002c ldr r0, [pc, #44] @ 10238 <main+0x74>
10208: ebffff96 bl 10068 <uart_puts>
1020c: e8bd4010 pop {r4, lr}
10210: e59f0024 ldr r0, [pc, #36] @ 1023c <main+0x78>
10214: eaffff93 b 10068 <uart_puts>
10218: e59f0020 ldr r0, [pc, #32] @ 10240 <main+0x7c>
1021c: ebffff91 bl 10068 <uart_puts>
10220: eafffff9 b 1020c <main+0x48>
このbeq命令が発火してジャンプが発生するとフラグが出力されますが、発火せずにジャンプが発生しないとフラグは出力されません。
通常の実行時には常にこのbeq命令が発火するためフラグが出力されませんが、もしこのbeq命令をスキップできればフラグを得られます。
スキップするタイミングの特定
beq命令の直前にプログラムが出力する文字は*drumroll*行の行末にある改行文字\nです。
この改行文字はプログラム全体で4回目の出現となっています。
サーバーから得られる観察ログでは、この文字周辺の出力タイミングは次の通りです。
[006291948544] ch = 0x6f
[006291955712] ch = 0x6c
[006291962880] ch = 0x6c
[006291970048] ch = 0x2a
[006291977216] ch = 0x0a
[009437734912] ch = 0x53
[009437742080] ch = 0x6f
[009437749248] ch = 0x72
[009437757440] ch = 0x72
[009437764608] ch = 0x79
beq命令の直前に出力される4回目の\nは、時間6291977216 nsに出力されています。
一方、beq命令の直後に出力される文字S (0x53)は、時間9437734912 nsに出力されています。
4回目の\n出力からbeq命令までの実行内容を検討すると、長いbusy loopを含むsleep関数の呼び出しが挟まっていますが、beq命令からS出力まで後方の実行内容を検討すると、ほぼ何も処理がなく、命令からすぐに文字が出力されています。
このため、トリガーとしては4回目の\n出力を指定しつつ、指定するoffset値は4回目\n出力 ~ S出力の経過時間を少しだけ減らしたものを指定すれば良さそうです。
beq命令からS出力(問題バナー記載の通り0x101f1000へのSTR命令)までに実行される命令数を数えると、11命令となっています。
この命令計数は、静的解析・動的解析・execlog(TCG Plugin)のいずれかで行うことを想定していますが、参考までにexeclogのトレース出力を示すと次の通りです。
0, 0x101f8, 0xa000006, "beq #0x10218"
0, 0x10218, 0xe59f0020, "ldr r0, [pc, #0x20]", load, 0x00010240, RAM
0, 0x1021c, 0xebffff91, "bl #0x10068"
0, 0x10068, 0xe5d01000, "ldrb r1, [r0]", load, 0x00010294, RAM
0, 0x1006c, 0xe3510000, "cmp r1, #0"
0, 0x10070, 0x12fff1e, "bxeq lr"
0, 0x10074, 0xe59f201c, "ldr r2, [pc, #0x1c]", load, 0x00010098, RAM
0, 0x10078, 0xe5923018, "ldr r3, [r2, #0x18]", load, 0x101f1018, pl011
0, 0x1007c, 0xe3130020, "tst r3, #0x20"
0, 0x10080, 0x1afffffc, "bne #0x10078"
0, 0x10084, 0xe5821000, "str r1, [r2]", store, 0x101f1000, pl011
問題概要にある通り、この処理系では約1024nsに1命令が実行されますから、スキップのタイミングとして指定すべきパラメーターを仮置きすると次の通りになります。
- Character
- 0x0a
- Count
- 4
- Offset
- (9437734912 – 6291977216) – 11 * 1024
しかし、このパラメーターでは、beq命令はスキップされません。
何故なら、バナーに「約1024nsに1命令」と書いた通り、このQEMUの命令実行速度は厳密に1024nsに1命令ではありません。
いくつかoffset値を変えて試行錯誤をしてみると、たまに、2048nsかけて1命令を実行するような挙動が見られます。
この挙動には、観察ログの解析と試行錯誤で気付いてもらうことを期待しています。
サーバー上でQEMUを動作させるときに、オプションとして「1024nsに1命令」を指定してあり(-icount shift=10)、何故そのような挙動になっているかは不明ですが、何らかの技術的制約ないしは作問上の問題によるものと思われます。
実際のFault Injection攻撃に際しても微妙な速度ズレが起こるため、今回は問題の一部として許容しています。
また、命令の実行速度には設定と微妙なズレがあるものの、このQEMUは決定的に動いており、何度実行しても常に同じタイミングで同じ命令を実行することや、観察ログに詳細な実行時間の情報を出力していることから、合理的な回数の試行錯誤で発見することを期待しています。
命令速度に仕様と微妙なズレがあるため、先述のパラメーターをベースにoffset値を近傍探索してもらうと、1命令分ズラした次のパラメーターでbeq命令がスキップされることが分かります。
- Character
- 0x0a
- Count
- 4
- Offset
- (9437734912 – 6291977216) – 12 * 1024 = 3145745408
この時、出力は次のようになります。
Welcome to Flag Provider Service!
The flag is ......
*drumroll*
IERAE{514ac1684b9c7a95cf26e0bf9}
Thank you for using our service!
Skip Skip Skip 2 (hard)
作問者: anonymous
正解チーム数: 6
概要
問題概要はSkip Skip Skip 1と全く同じで、実行するプログラムだけが変わったものです。
このプログラムを命令スキップ無しで通常通り実行すると、次の出力を得ます。
(InputにはEnterを1回入力しています)
Welcome to Secure Encryption Service!
Input:
Initializing the encryption engine...
Encrypting your data...
Encrypted data:
2a9877270220474c5c4adea10166929e249ed4afe757f77b76c701a563aa6585
Encryption complete.
Thank you for using our service!
解法
スキップする命令の特定
このプログラムはRC4の暗号化機能を提供します。
入力された任意の平文に対してフラグ(32byte)を暗号鍵として使ってRC4暗号化を行い、その結果を出力します。
このプログラムではフラグを出力する機能は無く、また1命令のスキップで直接フラグを出力できるような箇所もありません。
このため、RC4暗号化の機能と命令スキップを組み合わせて暗号鍵を特定する必要があります。
ソースコードを引用すると、RC4の暗号実装は次のようになっています。
void rc4_init(uint8_t *state, const uint8_t *key) {
int i, j;
uint8_t temp;
for (i = 0; i < 256; i++) {
state[i] = i;
}
for (i = 0, j = 0; i < 256; i++) {
j = (j + state[i] + key[i & (RC4_KEY_SIZE - 1)]) & 0xFF;
temp = state[i];
state[i] = state[j];
state[j] = temp;
}
}
void rc4_crypt(uint8_t *state, uint8_t *data, size_t datalen) {
size_t n;
uint8_t temp, k;
uint8_t i = 0, j = 0;
for (n = 0; n < datalen; n++) {
i = (i + 1) & 0xFF;
j = (j + state[i]) & 0xFF;
temp = state[i];
state[i] = state[j];
state[j] = temp;
k = state[(state[i] + state[j]) & 0xFF];
data[n] ^= k;
}
}
想定解は、rc4_init関数の2つ目のforループをi = 0-31でそれぞれ打ち切り、初期化が不完全な状態で暗号化を行って、鍵を1byteずつ推定するものです。
例えば、i = 0でこのforループを打ち切った場合、暗号鍵の先頭1byte目だけがRC4の内部状態に織り込まれた状態で暗号化が行われます。
そうすると、暗号文が取り得る値は暗号鍵の先頭1byte目に依存して256通りとなるので、手元で計算した値と比較すると、暗号鍵の先頭1byte目を特定できます。
これを32回繰り返すことで、32byteの暗号鍵全体を特定できます。
このforループのスコープ末尾は次のような機械語になっています。
101cc: e7d0c003 ldrb ip, [r0, r3]
101d0: e1550002 cmp r5, r2
101d4: e5c2c000 strb ip, [r2]
101d8: e7c0e003 strb lr, [r0, r3]
101dc: 1afffff3 bne 101b0 <rc4_init+0x2c>
101e0: e8bd8030 pop {r4, r5, pc}
101dcのbne命令がforループの続行条件判定であり、この命令をスキップするとforループを打ち切れます。
スキップするタイミングの特定
101dcのbne命令の直前にある文字出力は Initializing the encryption engine...\n 行末尾の改行文字\nであり、これは5回目に出現する\nです。
このため、CharacterとCountは次のように定まります。
- Character
- 0x0a
- Count
- 5
Offsetについては、静的解析結果とプログラムの出力を参考に探索することを期待しています。
例えば、rc4_init関数内にある1つ目のforループ内の命令をスキップした場合、その結果に応じて暗号文が変化しますから、rc4_init関数内の何処をスキップしているかが少しずつ探索できるようになっています。
探索の結果、offsetとして次の値を指定した時にi = 0-31で101dcがスキップされることが分かります。
OFFSETS = [
(1074 + 0 + 12 * 0) * 1024,
(1074 + 0 + 12 * 1) * 1024,
(1074 + 0 + 12 * 2) * 1024,
(1074 + 1 + 12 * 3) * 1024,
(1074 + 1 + 12 * 4) * 1024,
(1074 + 1 + 12 * 5) * 1024,
(1074 + 1 + 12 * 6) * 1024,
(1074 + 2 + 12 * 7) * 1024,
(1074 + 2 + 12 * 8) * 1024,
(1074 + 2 + 12 * 9) * 1024,
(1074 + 3 + 12 * 10) * 1024,
(1074 + 3 + 12 * 11) * 1024,
(1074 + 3 + 12 * 12) * 1024,
(1074 + 3 + 12 * 13) * 1024,
(1074 + 4 + 12 * 14) * 1024,
(1074 + 4 + 12 * 15) * 1024,
(1074 + 4 + 12 * 16) * 1024,
(1074 + 5 + 12 * 17) * 1024,
(1074 + 5 + 12 * 18) * 1024,
(1074 + 5 + 12 * 19) * 1024,
(1074 + 5 + 12 * 20) * 1024,
(1074 + 6 + 12 * 21) * 1024,
(1074 + 6 + 12 * 22) * 1024,
(1074 + 6 + 12 * 23) * 1024,
(1074 + 7 + 12 * 24) * 1024,
(1074 + 7 + 12 * 25) * 1024,
(1074 + 7 + 12 * 26) * 1024,
(1074 + 7 + 12 * 27) * 1024,
(1074 + 8 + 12 * 28) * 1024,
(1074 + 8 + 12 * 29) * 1024,
(1074 + 8 + 12 * 30) * 1024,
(1074 + 9 + 12 * 31) * 1024,
]
これら32通りのパラメーターを使い、適当な平文を入力した上で32通りの暗号文を得ることで、フラグ(暗号鍵)が求まります。
AVX-512 (hard)
作問者:SuperFashi
正解チーム数: 0
The challenge contains a single binary that has the following information:
avx512: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, BuildID[sha1]=fb2e4194c0923acf43189a7d54df7955dc4aa135, for GNU/Linux 3.2.0, stripped
Opening this binary inside a decompiler, you may quickly locate the main function at 0x4018d0. The main function contains a call into location 0x4018f0, outputs “wrong\n”, and then returns.
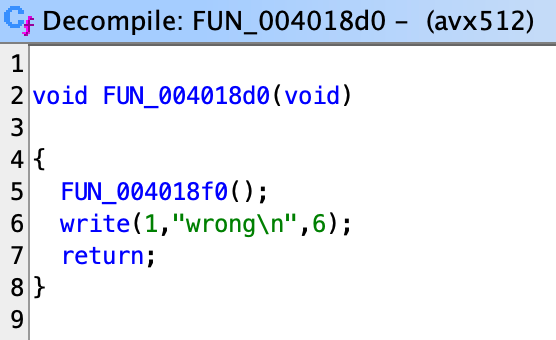
If you look into 0x4018f0, you will see a very confusing disassembler/decompiler output:
If you try to run the program, it works just fine (assuming your device supports AVX-512 instruction set). If you try to attach a debugger to it, however, you will find out that you would constantly receive a SIGTRAP signal, and none of the breakpoint/single-stepping works.
Apparently the program has some kind of obfuscation/anti-debugging technique, so let’s look into that.
Deobfuscation
First, we need to find out what is happening. First, if we look at the strace output, we see that SIGTRAP is emitted shortly after a call to rt_sigaction with SIGTRAP in its argument.
$ strace ./avx512
execve("./avx512", ["./avx512"], 0x7ffe034eca40 /* 22 vars */) = 0
brk(NULL) = 0x9ad7000
brk(0x9ad7d00) = 0x9ad7d00
arch_prctl(ARCH_SET_FS, 0x9ad7380) = 0
set_tid_address(0x9ad7650) = 74208
set_robust_list(0x9ad7660, 24) = 0
rseq(0x9ad7ca0, 0x20, 0, 0x53053053) = 0
prlimit64(0, RLIMIT_STACK, NULL, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
readlinkat(AT_FDCWD, "/proc/self/exe", "/home/ubuntu/avx512", 4096) = 19
getrandom("\x71\xad\x4c\x19\xa4\xbf\x28\x5b", 8, GRND_NONBLOCK) = 8
brk(NULL) = 0x9ad7d00
brk(0x9af8d00) = 0x9af8d00
brk(0x9af9000) = 0x9af9000
mprotect(0x4a9000, 20480, PROT_READ) = 0
rt_sigaction(SIGTRAP, {sa_handler=0x401830, sa_mask=[], sa_flags=SA_RESTORER|SA_SIGINFO, sa_restorer=0x4018c0}, NULL, 8) = 0
--- SIGTRAP {si_signo=SIGTRAP, si_code=TRAP_TRACE, si_addr=0x401821} ---
rt_sigreturn({mask=[]}) = 0
--- SIGTRAP {si_signo=SIGTRAP, si_code=TRAP_TRACE, si_addr=0x404c0c} ---
rt_sigreturn({mask=[]})
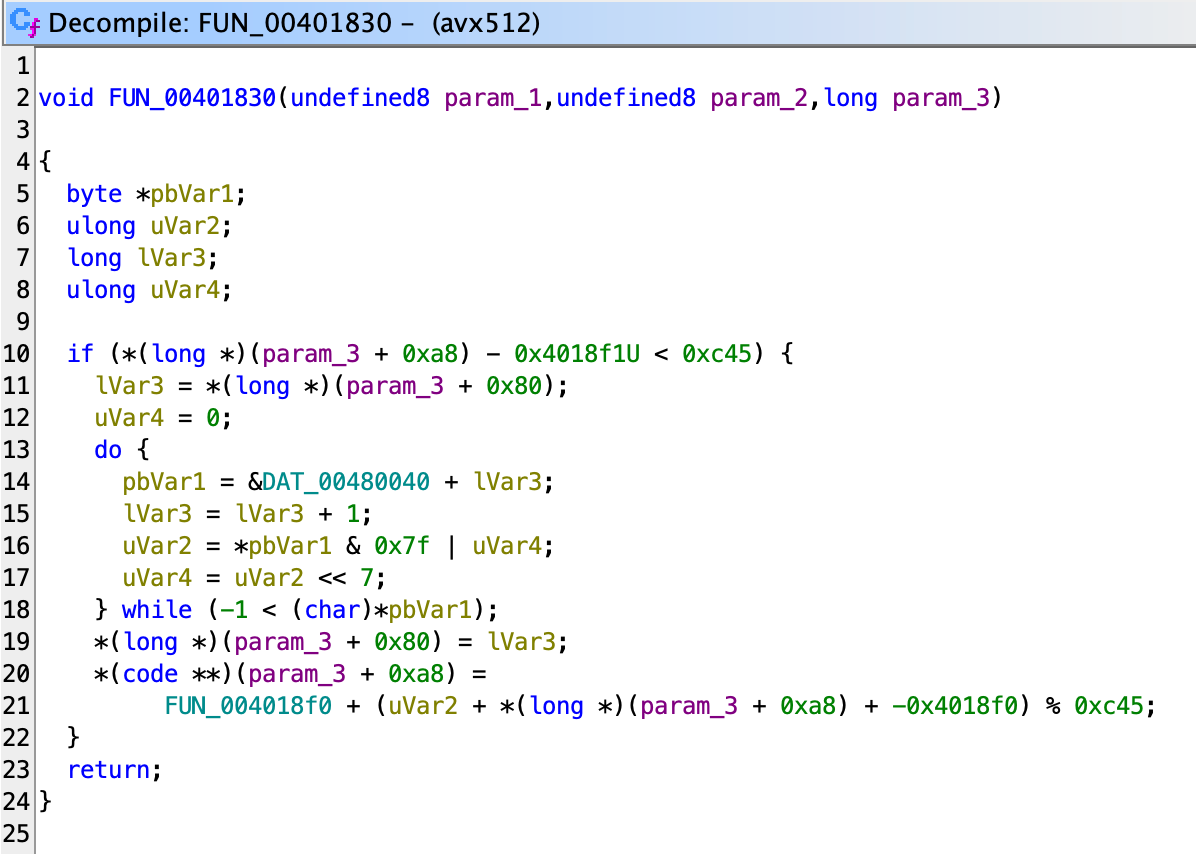
We also see that the signal handler is located at 0x401830, so we can go there in the decompiler and see the function that looks like this:
Now if we find cross references of this function, we see this function at 0x4017f0:
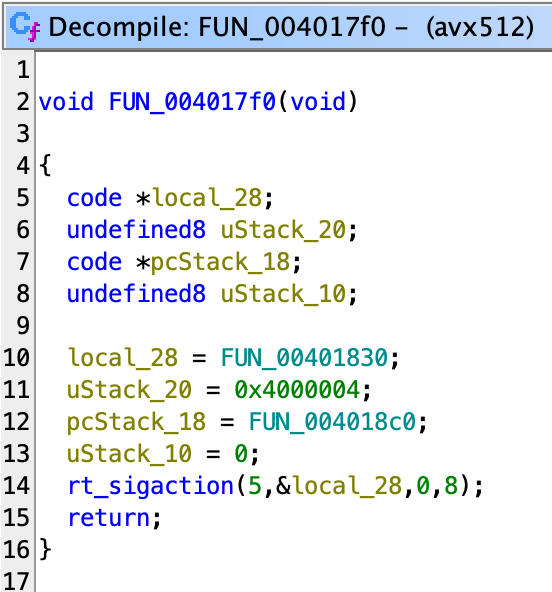
However, the decompiled code is missing an important part of the function, which needs us to look closer into the diassembled code:
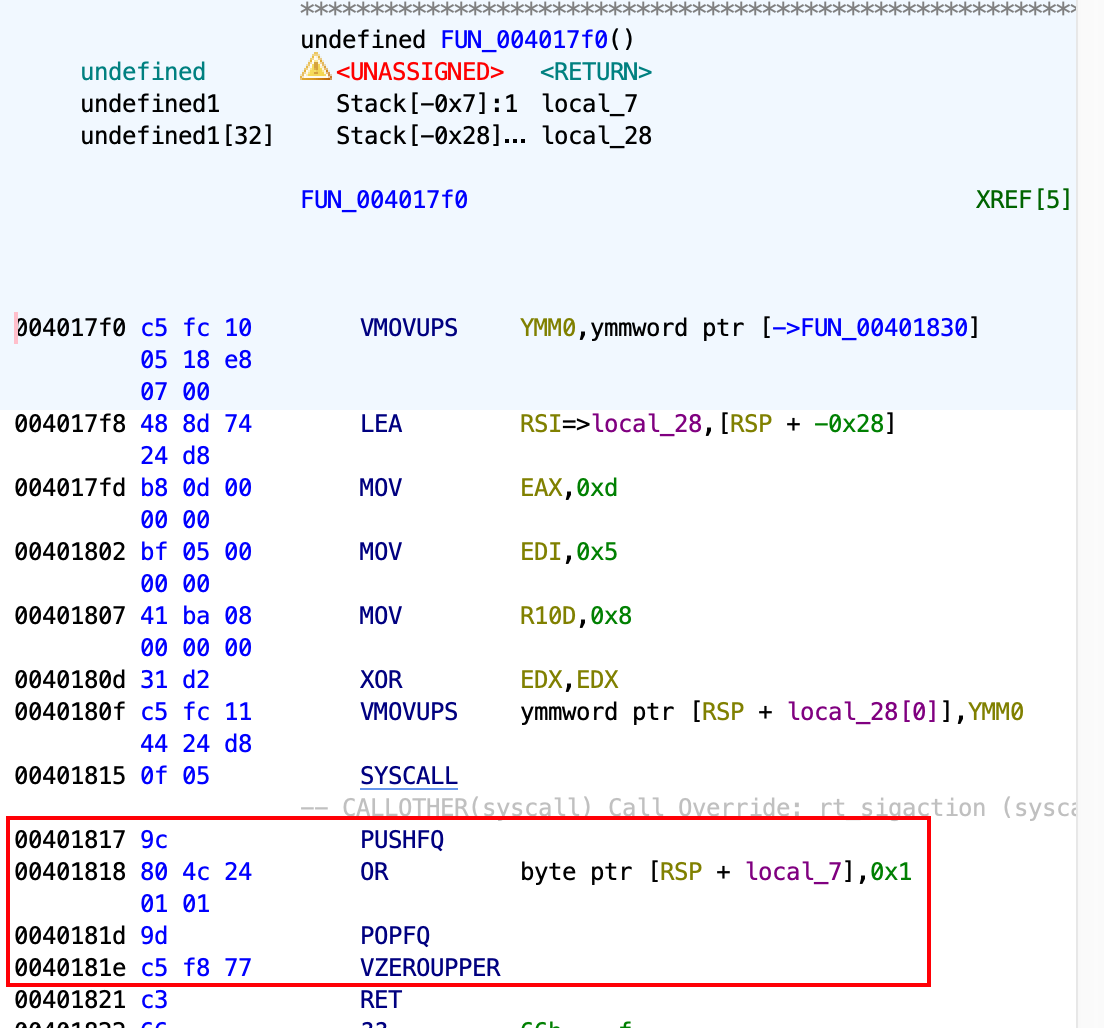
The code inside the red box actually set the bit 8 of the EFLAGS register to 1, which is the trap flag bit. After this bit is set, for every instruction executed, there’s gonna be a SIGTRAP signal emitted.
So let’s go back to our signal handler. First, since SA_SIGINFO is set, we know the signal handler’s signature should be (int, siginfo_t *, void *), where the last void * is actually a ucontext_t *. So we can clean it up a bit by setting the correct type:
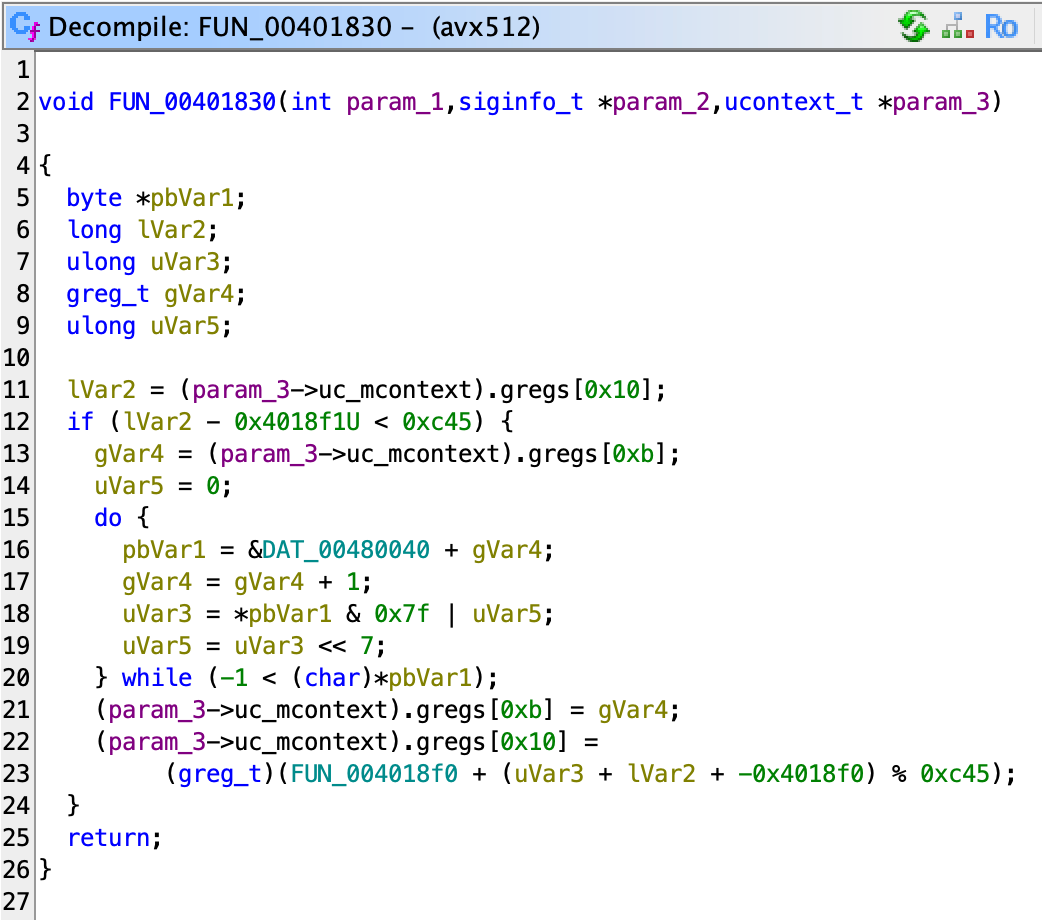
Looking at documentation, 0x10 is the RIP register, and 0xb is the RBX register. Then what this function does is:
- Read the current RIP register.
- If RIP is within the bounds of
0x4018f1to0x4018f1 + 0xc45. - Decode the
uvarintfrom0x480040 + $RBXintouVar3. - Set RBX register to the start of the next
uvarint. - Set RIP to
0x4018f0 + ($RIP - 0x4018f0 + uVar3) % 0xc45.
Recall that 0x4018f0 is where the weird function that cannot be decompiled begins, and therefore we can guess that 0xc45 is the size of data related to that function.
Essentially, this is an easy obfuscation step that makes the RIP jump around after executing every instruction. The jump amount is stored inside another array located at 0x480040 and encoded as a type of uvarint. The RBX register keeps track of the offset of the jump amount in the array.
The first instruction in the obfuscated function is xor ebx, ebx which sets rbx to 0. From then, the signal handler would begin to read in the offsets and apply to RIP. Understanding that, we can write a simple function that dumps the obfuscated instruction:
import cle
import capstone
import capstone.x86_const as csc
OFFSET_STORE = 0x480040
CODE_STORE = 0x4018F0
SIZE = 0xC45
binary = cle.Loader("avx512")
cs = capstone.Cs(capstone.CS_ARCH_X86, capstone.CS_MODE_64)
RIP = CODE_STORE
RBX = 0
while True:
code = binary.memory.load(RIP, 16)
instn = next(cs.disasm(code, RIP, 1))
print(instn)
RIP += instn.size
if instn.mnemonic == "ret":
break
# load uintvar
jmp = 0
while True:
val = binary.memory.load(OFFSET_STORE + RBX, 1)[0]
RBX += 1
jmp |= val & 0b111_1111
if val & 0b1000_0000 != 0:
break
jmp <<= 7
off = (RIP - CODE_STORE + jmp) % SIZE
RIP = CODE_STORE + off
And we get the following output:
<CsInsn 0x4018f0 [31db]: xor ebx, ebx>
<CsInsn 0x401c29 [488d7424c0]: lea rsi, [rsp - 0x40]>
<CsInsn 0x402418 [8d834e890e00]: lea eax, [rbx + 0xe894e]>
<CsInsn 0x4019f8 [4869c07b913702]: imul rax, rax, 0x237917b>
<CsInsn 0x401f25 [488906]: mov qword ptr [rsi], rax>
<CsInsn 0x40217b [8d43f5]: lea eax, [rbx - 0xb]>
<CsInsn 0x401df3 [89c7]: mov edi, eax>
<CsInsn 0x4024b4 [8d53f5]: lea edx, [rbx - 0xb]>
<CsInsn 0x401af3 [0f05]: syscall >
<CsInsn 0x402427 [f9]: stc >
Traceback (most recent call last):
File "dump.py", line 16, in <module>
instn = next(cs.disasm(code, RIP, 1))
StopIteration
Everything seems to work fine until syscall. This is the first trap in the obfuscation, which is that since syscall instruction emits its own interruption that allows OS to enter kernel space, where during the context switch the EFLAGS are backed up and cleared, we don’t get a SIGTRAP after the syscall instruction.
We can just change our “disassembler” to handle this situation as well.
...
if instn.mnemonic == "ret":
break
+ if instn.mnemonic == "syscall":
+ continue
# load uintvar
...
Now we have a bit more output:
<CsInsn 0x4018f0 [31db]: xor ebx, ebx>
<CsInsn 0x401c29 [488d7424c0]: lea rsi, [rsp - 0x40]>
<CsInsn 0x402418 [8d834e890e00]: lea eax, [rbx + 0xe894e]>
<CsInsn 0x4019f8 [4869c07b913702]: imul rax, rax, 0x237917b>
<CsInsn 0x401f25 [488906]: mov qword ptr [rsi], rax>
<CsInsn 0x40217b [8d43f5]: lea eax, [rbx - 0xb]>
<CsInsn 0x401df3 [89c7]: mov edi, eax>
<CsInsn 0x4024b4 [8d53f5]: lea edx, [rbx - 0xb]>
<CsInsn 0x401af3 [0f05]: syscall >
<CsInsn 0x401af5 [8d532d]: lea edx, [rbx + 0x2d]>
<CsInsn 0x40242a [31c0]: xor eax, eax>
<CsInsn 0x4020c0 [ffcf]: dec edi>
<CsInsn 0x401955 [0f05]: syscall >
<CsInsn 0x401957 [8d4b05]: lea ecx, [rbx + 5]>
<CsInsn 0x401fb7 [38c8]: cmp al, cl>
<CsInsn 0x402351 [0f97c0]: seta al>
<CsInsn 0x40241d [00c3]: add bl, al>
<CsInsn 0x402423 [c3]: ret >
Let’s figure out what this short piece of code is doing. For the first syscall, we don’t see any constants actually loaded into the arguments. Instead, they are all some kind of weird form of lea <reg>, [rbx +/- <constant>].
This turns out to be a constant obfuscation based on the rbx value, which, if we recall, is changed in the signal handler to keep track of the index of the jump offset array. We can therefore turn these instructions into normal mov by calculating their actual value.
...
instn = next(cs.disasm(code, RIP, 1))
- print(instn)
+ if instn.mnemonic == "lea" and instn.operands[1].mem.base == csc.X86_REG_RBX:
+ assert instn.operands[1].mem.index == 0
+ constant = RBX + instn.operands[1].mem.disp
+ print(f'{hex(instn.address)}:\tmov {instn.op_str.split(", ")[0]}, {hex(constant)}')
+ else:
+ print(f'{hex(instn.address)}:\t{instn.mnemonic} {instn.op_str}')
RIP += instn.size
...
Now we have
0x4018f0: xor ebx, ebx
0x401c29: lea rsi, [rsp - 0x40]
0x402418: mov eax, 0xe8952
0x4019f8: imul rax, rax, 0x237917b
0x401f25: mov qword ptr [rsi], rax
0x40217b: mov eax, 0x1
0x401df3: mov edi, eax
0x4024b4: mov edx, 0x6
0x401af3: syscall
0x401af5: mov edx, 0x40
0x40242a: xor eax, eax
0x4020c0: dec edi
0x401955: syscall
0x401957: mov ecx, 0x20
0x401fb7: cmp al, cl
0x402351: seta al
0x40241d: add bl, al
0x402423: ret
Now the syscall makes more sense: The first syscall is write to stdout with argument buffer located at rsp - 0x40, and 6 as length. The second syscall is read from stdin with the same buffer, and 64 as length. The string to write is
>>> (0xe8952 * 0x237917b).to_bytes(6, 'little')
b'flag: '
Which you can also see if you run the binary. The last part roughly translates to
bl += read_syscall_return_value > 0x20;
Which might be confusing at first, but remember: bl is the low 8 bit of the register rbx—rbx controls the index in the jump offset array—then changing bl could potentially change the jump amount. This actually is how the obfuscation implements branching. In this case, the amount of data read must be larger than 32 bytes for bl to increase by one.
We can write a fix that unconditionally makes the branch “true”:
...
if instn.mnemonic == "syscall":
continue
+ if instn.mnemonic == "add" and instn.operands[0].reg == csc.X86_REG_BL:
+ rbx += 1
# load uintvar
...
Finally we got a lot more code. Unfortunately there’s still one more issue:
0x401d13: xor ecx, ecx
0x4024a9: mov rdi, qword ptr [rip + 0x44c7c]
0x402207: vmovups ymmword ptr [rsi], ymm7
0x401963: jmp 0x402457
Traceback (most recent call last):
File "dump.py", line 18, in <module>
instn = next(cs.disasm(code, RIP, 1))
StopIteration
We have met with a jmp instruction. Although it may look scary, if we just implement jmp as-is in our dumper:
...
if instn.mnemonic == "ret":
break
+ if instn.mnemonic == "jmp":
+ assert len(instn.operands) == 1
+ assert instn.operands[0].type == capstone.CS_OP_IMM
+ RIP = instn.operands[0].imm
if instn.mnemonic == "syscall":
continue
...
We seem to get the full dump now! Now let’s refactor our code and print both branches:
import cle
import capstone
import capstone.x86_const as csc
OFFSET_STORE = 0x480040
CODE_STORE = 0x4018F0
SIZE = 0xC45
binary = cle.Loader("avx512")
cs = capstone.Cs(capstone.CS_ARCH_X86, capstone.CS_MODE_64)
cs.detail = True
def load_uvarint(rbx):
jmp = 0
while True:
val = binary.memory.load(OFFSET_STORE + rbx, 1)[0]
rbx += 1
jmp |= val & 0b111_1111
if val & 0b1000_0000 != 0:
break
jmp <<= 7
return jmp, rbx
def trace(rip, rbx):
code = binary.memory.load(rip, 16)
instn = next(cs.disasm(code, rip, 1))
if instn.mnemonic == "lea" and instn.operands[1].mem.base == csc.X86_REG_RBX:
assert instn.operands[1].mem.index == 0
constant = rbx + instn.operands[1].mem.disp
print(f'{hex(instn.address)}:\tmov {instn.op_str.split(", ")[0]}, {hex(constant)}')
else:
print(f"{hex(instn.address)}:\t{instn.mnemonic} {instn.op_str}")
rip += instn.size
if instn.mnemonic == "ret":
return
if instn.mnemonic == "jmp":
assert len(instn.operands) == 1
assert instn.operands[0].type == capstone.CS_OP_IMM
rip = instn.operands[0].imm
if instn.mnemonic == "syscall":
return trace(rip, rbx)
if instn.mnemonic == "add" and instn.operands[0].reg == csc.X86_REG_BL:
print("False ->")
jmp, new_rbx = load_uvarint(rbx)
off = (rip - CODE_STORE + jmp) % SIZE
trace(CODE_STORE + off, new_rbx)
print("True ->")
rbx += 1
jmp, new_rbx = load_uvarint(rbx)
off = (rip - CODE_STORE + jmp) % SIZE
return trace(CODE_STORE + off, new_rbx)
trace(CODE_STORE, 0)
We again got an issue:
True ->
0x401a7d: vmovdqa64 ymm5, ymm7
0x401c12: vpermb ymm7, ymm6, ymm5
0x40218e: xor dl, dl
0x401d13: xor ecx, ecx
0x4024a9: mov rdi, qword ptr [rip + 0x44c7c]
0x402207: vmovups ymmword ptr [rsi], ymm7
0x401963: jmp 0x402457
0x401c91: mov al, dil
0x401c67: shr rdi, 1
0x401999: mul byte ptr [rsi + rcx]
0x401ddc: add dl, al
0x402406: mov eax, 0x20
0x40223f: inc ecx
0x40194a: cmp cl, al
0x401b87: sete al
0x40241d: add bl, al
False ->
0x402454: sub ebx, 0x1b
Traceback (most recent call last):
File "dump.py", line 64, in <module>
trace(CODE_STORE, 0)
...
Here, we met the situation where in the false branch, we don’t get the normal ret, but instead a weird sub ebx, 0x1b. This is actually the way this obfuscation implements loop. To make it easier to understand, let’s output the RBX register values and the corresponding jump amount on the side:
0x401a7d: vmovdqa64 ymm5, ymm7 (rbx: 0x6b8, jmp: 0xa8cdb)
0x401c12: vpermb ymm7, ymm6, ymm5 (rbx: 0x6bb, jmp: 0x766f8)
0x40218e: xor dl, dl (rbx: 0x6be, jmp: 0x4ba32)
0x401d13: xor ecx, ecx (rbx: 0x6c1, jmp: 0x794)
0x4024a9: mov rdi, qword ptr [rip + 0x44c7c] (rbx: 0x6c3, jmp: 0x109ede)
0x402207: vmovups ymmword ptr [rsi], ymm7 (rbx: 0x6c6, jmp: 0x39d)
0x401963: jmp 0x402457 (rbx: 0x6c8, jmp: 0x41d8)
0x401c91: mov al, dil (rbx: 0x6cb, jmp: 0x964a7)
0x401c67: shr rdi, 1 (rbx: 0x6ce, jmp: 0x2f5e5)
0x401999: mul byte ptr [rsi + rcx] (rbx: 0x6d1, jmp: 0x17e27a)
0x401ddc: add dl, al (rbx: 0x6d4, jmp: 0x628)
0x402406: mov eax, 0x20 (rbx: 0x6d6, jmp: 0x1cb3a6)
0x40223f: inc ecx (rbx: 0x6d9, jmp: 0x1360b)
0x40194a: cmp cl, al (rbx: 0x6dc, jmp: 0x69f6d)
0x401b87: sete al (rbx: 0x6df, jmp: 0x1b667a)
0x40241d: add bl, al (rbx: 0x6e2, jmp: 0x35)
False ->
0x402454: sub ebx, 0x1b (rbx: 0x6e3, jmp: 0x61e)
And if we calculate 0x6e3 - 0x1b we get 0x6c8, which is where the weird jmp located at. This means, after the instruction is executed, our signal handler will actually read the jump value corersponded to the jmp 0x402457 instruction, which is 0x41d8, and the jump amount therefore will be <start> + (0x402454 + <size of sub> + 0x41d8 - <start>) % <size>, which results in 0x401c91, the instruction after jmp.
In order to compensate for this jump amount for the final jumping back to the start of the loop, we introduced the extra jmp instruction that would result in the same instruction (<start> + (0x402457 + 0x41d8 - <start>) % <size> = 0x401c91).
Finally, we have the fully functioning dumper:
import cle
import capstone
import capstone.x86_const as csc
OFFSET_STORE = 0x480040
CODE_STORE = 0x4018F0
SIZE = 0xC45
binary = cle.Loader("avx512")
cs = capstone.Cs(capstone.CS_ARCH_X86, capstone.CS_MODE_64)
cs.detail = True
def load_uvarint(rbx):
jmp = 0
while True:
val = binary.memory.load(OFFSET_STORE + rbx, 1)[0]
rbx += 1
jmp |= val & 0b111_1111
if val & 0b1000_0000 != 0:
break
jmp <<= 7
return jmp, rbx
def trace(rip, rbx):
while True:
code = binary.memory.load(rip, 16)
instn = next(cs.disasm(code, rip, 1))
rip += instn.size
if instn.mnemonic == "sub" and instn.operands[0].reg == csc.X86_REG_EBX:
assert instn.operands[1].type == capstone.CS_OP_IMM
jmp, _ = load_uvarint(rbx - instn.operands[1].imm)
off = (rip - CODE_STORE + jmp) % SIZE
print(f"{hex(instn.address)}:\tjmp {hex(CODE_STORE + off)}")
return
if instn.mnemonic == "jmp":
pass
elif instn.mnemonic == "lea" and instn.operands[1].mem.base == csc.X86_REG_RBX:
assert instn.operands[1].mem.index == 0
constant = rbx + instn.operands[1].mem.disp
print(f'{hex(instn.address)}:\tmov {instn.op_str.split(", ")[0]}, {hex(constant)}')
else:
print(f"{hex(instn.address)}:\t{instn.mnemonic} {instn.op_str}")
if instn.mnemonic == "ret":
return
if instn.mnemonic == "jmp":
assert len(instn.operands) == 1
assert instn.operands[0].type == capstone.CS_OP_IMM
rip = instn.operands[0].imm
if instn.mnemonic == "syscall":
continue
if instn.mnemonic == "add" and instn.operands[0].reg == csc.X86_REG_BL:
print("False ->")
jmp, new_rbx = load_uvarint(rbx)
off = (rip - CODE_STORE + jmp) % SIZE
trace(CODE_STORE + off, new_rbx)
print("True ->")
rbx += 1
jmp, rbx = load_uvarint(rbx)
off = (rip - CODE_STORE + jmp) % SIZE
rip = CODE_STORE + off
trace(CODE_STORE, 0)
Code structure
If you have a powerful LLM, you could try to throw the entire code dump to it and see if it gives any interesting insight. For me, it worked semi-well as to getting the general structure of the code, which is actually a system of linear equations modulo 256.
To analyze more closely, there’s a few points of structure that can either be reconginized by eyeballing, or through hints from AI. We could use branching instructions (that always is in the form of add bl, <some other reg>) as a separation rule for all the parts.
- There’s the first part of input handling, which we already kind of analyzed.
- The program stores 64-bytes of the input buffer into
zmm7register (which is an AVX-512 register). - Then there’s a simple checking of the prefix and suffix of the flag, which starts with
IERAE{and the 33th byte is}. This also tells us the flag is of length 33. - Then there’s a small block of code has some AVX-512 instructions.
- After that, there are 25 blocks that have the similar structure (except for the 10th and 20th block), each begins with a very iconic
vpermb ymm7, ymm6, ymm5(and randomlyvpermb ymm6, ymm5, ymm5). - Within each of the big blocks, there are 4 small blocks of similar structure, each begins with some form of loading from
zmm7, and also some form of loading from[rip + <random value>]. - At the end of the big blocks, it has the same branching we see above, where the calculation is compared with a constant, and
retif it does not match.
Let’s first figure out what the first small block with AVX-512 instructions is doing:
0x401db3: vxorps ymm7, ymm7, ymmword ptr [rip - 0x26d]
0x4019ca: vextracti32x4 xmm0, ymm7, 1
0x401f77: vpaddb xmm0, xmm0, xmm7
0x401ac8: mov ecx, 0x17
0x4021d3: vpsrldq xmm1, xmm0, 8
0x4024c5: vpaddb xmm0, xmm0, xmm1
0x401b4b: vpxor xmm1, xmm1, xmm1
0x401b18: vpsadbw xmm0, xmm0, xmm1
0x401d8b: vpextrb eax, xmm0, 0
0x40194a: cmp cl, al
0x401fd5: sete dl
0x40225f: add bl, dl
False ->
0x4022b9: ret
True ->
0x401dd5: vmovups ymm6, ymmword ptr [rip + 0x287]
[next block]
For the initial vxorps: It’s basically the same as xor. This xors the input (flag located at ymm7) with a ymmword at RIP - 0x26d.
For the remaining code, you could either lookup documentation of each AVX-512 instruciton, or you can put them into LLM and it should give a nice explanation:

So essentially, this is an AVX-512 version to sum all the first 32 bytes in the flag, store it in a byte (effectively mod 256), and compare it with the constant 0x17. In linear algebra form, this would be equivalent to a dot product with a vector of all 1s.
At the end, there is a vmovups (which is essentially a mov) which loads a ymmword data from rip + 0x287. If you dump the content, you will see that it is a permutation from 0 to 31, which will be useful later.
Let’s then figure out what 10th block is doing:
0x401a7d: vmovdqa64 ymm5, ymm7
0x401c12: vpermb ymm7, ymm6, ymm5
0x40218e: xor dl, dl
0x401d13: xor ecx, ecx
0x4024a9: mov rdi, qword ptr [rip + 0x44c7c]
0x402207: vmovups ymmword ptr [rsi], ymm7
0x401c91: mov al, dil
0x401c67: shr rdi, 1
0x401999: mul byte ptr [rsi + rcx]
0x401ddc: add dl, al
0x402406: mov eax, 0x20
0x40223f: inc ecx
0x40194a: cmp cl, al
0x401b87: sete al
0x40241d: add bl, al
False ->
0x402454: jmp 0x401c91
True ->
0x401df8: mov eax, 0x59
0x40196a: cmp dl, al
0x401b87: sete al
0x40241d: add bl, al
False ->
0x402423: ret
True ->
[next block]
Actually, only vmovdqa64, vpermb and vmovups is AVX-512 instructions, the other instructions are pretty normal and can be decompiled by tools/LLM. For the three AVX-512 instructions, looking at document we can understand that vmovdqa64 and vmovups functions similarly to mov, and vpermb permutes the bytes.
So the initial vmovdqa64 ymm5, ymm7 and vpermb ymm7, ymm6, ymm5 simply permutes ymm7 according to the content of ymm6. ymm6 as we know before, contains a permutation of 0 to 31, therefore this instruction is basically shuffling the flag (at ymm7) according to the content of ymm6. You will see these two instructions marking the start of the blocks we’ll see.
The main part of the function can be roughly decompiled as:
sum = 0
constant = *(uint64_t)(rip + 0x44c7c)
for (i := 0 .. 31)
sum += ymm7[i] * (constant & 0xff)
constant >>= 1
if (sum & 0xff != 0x59)
return
Essentially a linear equation where the row vector element i is (<constant> >> i) & 0xff. When calculating it, just be careful to correctly shuffles the flag or unshuffles the row vector to solve for the system of equations.
For the 20th block, we have:
0x401a7d: vmovdqa64 ymm5, ymm7
0x401c12: vpermb ymm7, ymm6, ymm5
0x40218e: xor dl, dl
0x401d13: xor ecx, ecx
0x402207: vmovups ymmword ptr [rsi], ymm7
0x401c84: mov al, byte ptr [rsi + rcx]
0x40223f: inc ecx
0x4019ea: mul cl
0x401ddc: add dl, al
0x4024bb: mov eax, 0x20
0x40194a: cmp cl, al
0x401b87: sete al
0x40241d: add bl, al
False ->
0x40242e: jmp 0x401c84
True ->
0x40247a: mov eax, 0x66
0x40196a: cmp dl, al
0x401b87: sete al
0x40241d: add bl, al
False ->
0x402423: ret
True ->
[next block]
This is very similar to the 10th block, and can be roughly translated to
sum = 0
for (i := 1 .. 32)
sum += ymm7[i - 1] * i
if (sum & 0xff != 0x66)
return
Essentially another linear equation where the row vector is filled from 1 to 32.
Finally, let’s analyze the big blocks, which has 23 of them, and within each big block there’re 4 small blocks. This might seem like a lot, but the hope is that after a few blocks of analysis, you could quickly find the pattern and see all of them follows this pattern.
Let’s see an example of such small blocks:
0x40239e: vmovd xmm0, dword ptr [rip + 0x37a07]
0x401a67: vpsrldq xmm1, xmm7, 4
0x40205d: vpmovzxbw xmm1, xmm1
0x401eff: vpmovzxbw xmm0, xmm0
0x401b42: vpmullw xmm0, xmm0, xmm1
0x401b4b: vpxor xmm1, xmm1, xmm1
0x401e52: vpshufb xmm0, xmm0, xmmword ptr [rip - 0x441]
0x402093: vinsertps xmm0, xmm0, xmm0, 0xe
0x401b18: vpsadbw xmm0, xmm0, xmm1
0x401e1b: vpextrb ecx, xmm0, 0
0x401ccd: add dl, cl
It’s full of AVX-512 operations. Let’s first load the xmmword from RIP - 0x441, which is 0x401e52 + <size of vpshufb> - 0x441 = 0x401a18, where the data is [0, 2, 4, 6, 8, 10, 12, 14, 0, 2, 4, 6, 8, 10, 12, 14]. Again, you could read the documentation and figure out what it does, or just feed it into LLM:

As we can see, it’s just another form of dot product. More specifically, it calculates the dot product of xmm7[4:8] and 4 bytes stored at RIP + 0x37a07 and add it to dl. Indeed, for all such small blocks, what it does is to load a constant from RIP + <random value>, dot product with a part of the flag, and accumulate the result in one register.
To automate this process, argubly the hardest part is to figure out the size and the offset in the ymm7/xmm7 (flag input after shuffling) is used for dot product. There’s a few ways to do it:
- Ask LLM to extract the parameters for you. In actual practice, this gives a pretty good result, but will be annoying if it messes up one or two places, where you have to painstakingly find out where.
- Use some smart tricks such as:
- Look at the operand size that loads from
rip + <random value>. This size is the same as the size picked from the flag. - Load a fake value
[0, 1, 2, ..., 31]intoymm7, and override the constant as[1, 1, ..., 1](all 1s). Then run the extracted code as a shellcode with the registers in place. In this way, the final dot product would result in a value that iswhich you can solve for
, that is the offset of the input.
- Look at the operand size that loads from
After 4 small blocks in each big block, there will be finally a check on the sum of all dot product. It is easy to see that the sum of all dot products with the same vector on one side (the flag input) is equivelent to a single dot product of the that vector multiplies with the sum of all vectors on the other side. In which case, the whole big block is actually a dot product.
So essentially, we got 26 dot products (1 total sum, 2 loops sums, and 23 blocks of SIMD sums). Plus the 6 characters we know from the initial check IERAE{, we have 32 unknowns and 32 equations. Solving for the unknowns yields the final flag.
GMOPass (extreme)
作問者:SuperFashi
正解チーム数: 0
The challenge contains a docker compose configuration and a single dynamic library that has the following information:
GMOPass.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=3a7f07a3c86f923655d1b19b5f82e5c6545174c6, stripped
Looking at the Dockerfile and run file, we can figure out that this is suppose to work together with clang and used as a pass plugin.
Briefly, the pass plugin takes in the LLVM IR and can do a bunch of different operations to it. It could do analysis or optimization, or in this case, the plugin actually contains a LLVM IR interpreter that plays a game of snake(!). We’ll talk more about it later.
Reversing
First let’s do some reverse engineering. We can quickly locate to where the flag is from string search:

We see that the flag would get printed in function 0x102c10 if bVar4 is true and param_2 + 0x31 equals 64. Here, bVar4 is actually the return value of functionat 0x102fb0, and although we don’t know what param_2 + 0x31 is yet, we can create a new type for param_2 so we can keep track of it. In fact, let’s just call the name of the struct (class) GMOPass.
Slightly before this, we see calls into the Clang library:

There’re two getGlobalVariable calls and one getFunction call. Looking at documentation, you can know that they take in llvm::StringRef. However, the strings here are actually obfuscated, so they don’t show up directly. You can either attach debugger to see what the actual string is, or reverse this obfuscation, which is actually just a simple open-source implmentation over here.
In short, the code is actually getting two global variables, one called input and one called output, and one function called main from the LLVM module. If these doesn’t exist, it will return. There are some extra checks for the output variable and main function from the code, but without proper symbols it is hard to figure out what they are checking. In any case we can skip them for now, or it is also possible to get the struct memory layout through compiling you own LLVM.
Let’s start looking at 0x102fb0, which is huge. We can take steps approaching it:
- The first argument of function
0x102fb0is the same structGMOPass. - The second argument is passed in from
param_3 + 0x120, where we knowparam_3is of typellvm::Module *, so with some experiment, we see+ 0x120is justdataLayoutof the module. - The third argument is the
mainfunction we just got. - Cross-referencing the winning condition variable (
+0x31) in the function, we see it is only used in one place:
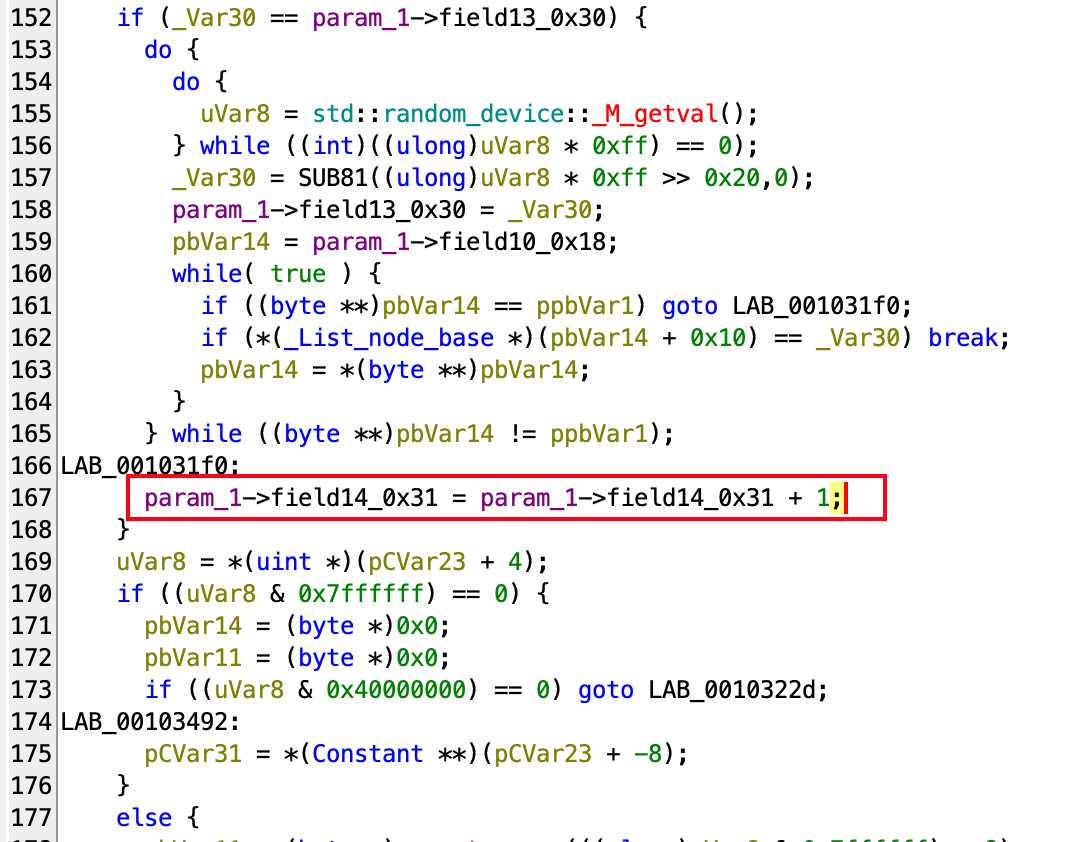
which increases by one. This means it’s some sort of counter. - Actually, the increase only happens when (at line 152) the condition is true. And by slightly reading the code, we can see there is a doubly linked list implementation (or the
_List_node_baseshould tell you). After setting the correct structure, we have

Here we can also just ask LLM to convert it back to more clear C++, but it should be pretty clear that this code has the following logic:- if
uVar30 != this->field11_0x30, we pop an element from the tail of the list. - We iterate through the list and if there’s an element equals
uVar30, we return. - Otherwise, we add
uVar30to the head of the list. - If
uVar30 == this->field11_0x30, we generate a random number that is between 0 and 0xff. - If the generated random number is in the list, we reroll.
- Otherwise, we add the counter by 1.
- if
- Looking further up, we can see that
uVar30has the following assigning logic:
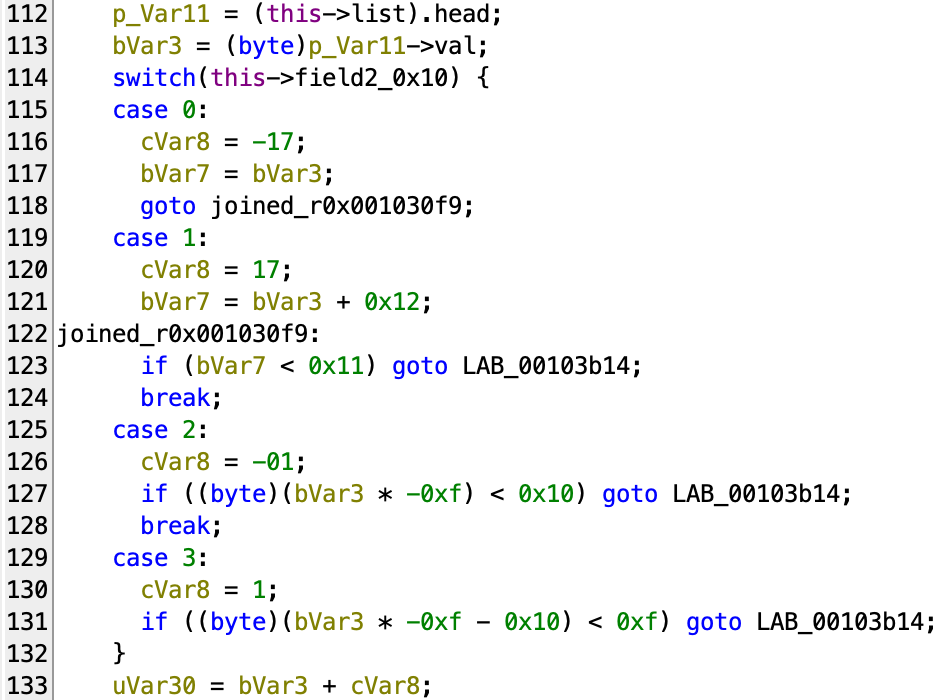
It’s a simple switch case depending on the value ofthis->field2_0x10. AndcVar8is derived from that value. We also have checks on the currentbVar3value, which is the value at the head of the list:- For case 0,
bVar3should be greater than 0x11. - For case 1,
bVar3should be less than 0xee (). - For case 2,
bVar3mod 0x11 should not be 0 (and ). - For case 3, similarly,
bVar3mod 0x11 should not be0x10.
And finallyuVar30is the sum ofbVar3andcVar8.
- For case 0,
Now, if you are lucky, your LLM or instinct might already tell you this is some kind of game. Since we already said that this is a game of Snake, this should not be too unfamilar to you:
- The list stores the position of the snake body.
bVar3, being the head of the list, is the head of the snake.- The board is of size 15×17. The position is encoded into a single
uint8_t(row * 17 + col). uVar30is the next position according to the movement direction (this->field2_0x10).- The movement direction has 4 possible choices, which corresponding to +17, -17, -1, +1 on the location. (the above switch code is then the bound check).
- If the
headintersects with any part of the body, game over. this->field11_0x30is the position of the food.- If the food is eaten, we randomly generate the food position on the board that is not on the snake.
- And finally, we increase the important counter. This means the counter is number of food eaten. And the game wins if we can get 64 of them.
If you still couldn’t arrive at this, that’s fine as it’s possible to make the realization after reversing more.
Now, getting the hang of the game, how do we actually play it? Let’s find the cross reference to the movement direction first. We see that there’s two references, one is at the function 0x102c10, right underneath when we get the output global variable:
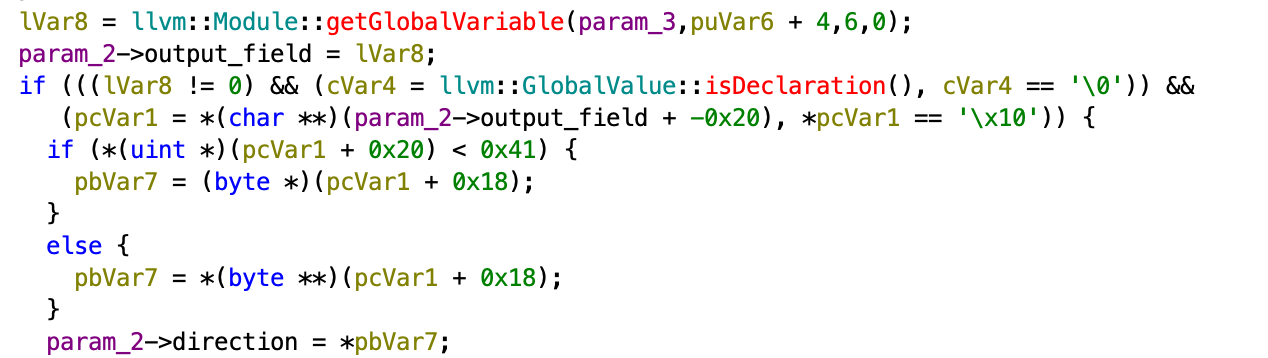
Although we don’t have symbols, it is easy to guess from isDeclaration that we are getting the variable declaration value and set it as the direction.
The other location is similar, but slightly more convoluted to reverse as it involves variable tracking through maps, and handling LLVM IR code. The usage is actually through LLVM’s store instruction, which when you store into output variable, you are effectively setting the direction of the snake.
Our intention is actually that you can half-guess the usage based on knowledge about LLVM, some AI assistance, and with some experimentation and understanding of the snake game. Maybe you will be writing the misc part and suddenly realize you have missed something, and that’s fine.
The other part, which is what the input variable is used for, can also be found through cross referencing:

Again, the code looks convoluted, but the hope here is that you can kind of see the connection of input field and food location: The food would be converted into a 2-byte data [row, col], and whenever you load from input, the value would be the location of the current food.
The rest of the code is mainly for interpreter, where the author tried his best to support as much useful operations as possible. However, there’s one other very important thing to notice, which is this field here:

We actually have another counter, that when exceeding 4896, is going to make the function return false. We can also see that all the logic we have just analyzed (snake moving, etc.) is all after this ticker. Therefore we can deduct that this is basically a timer in the game, and the game is actually time-limited.
One more important thing, if you look at where this code is located, it’s actually around middle of the main loop in that function, and there are some early continues before that code. This means for some cases, the timer is not ticked. To figure out what exactly makes the counter tick, we can take a look at the code in between the start of the loop and that check:

As we can see, there are three main branches that escapes the ticking, especially when the highlighted variables equals to 29, 30, and 31. Here we actually have the operand code of LLVM Instruction, and through some source code reading/documentation, we can see that these actually corresponds to ret, branch, and switch instructions. This means, when these instruction are executed, the game is not actually played.
Again, you may actually only realize this when you are writing the misc part, but that is fine.
In case you haven’t realized it: the game will play a tick (snake move a cell) whenever an LLVM instruction is interpreted, unless it’s ret, branch, or switch (and actually, phi as well). And the whole crux of the game is, your code have to play the snake game autonomously at the same time your code is interpreted line-by-line.
Finally, you could find out the initial conditions pretty easily:
- At the start of the game, the snake occupies three cells:
(7, 1), (7, 2), (7, 3). - The food initially is at
(7, 12).
And let’s summarize the things we know:
- The game is snake, and the board size is 15 x 17.
- The target is to code in LLVM IR that could play the snake game through loading from a global variable
input(uint8_t[2] = {x, y}, the food position), and storing tooutput(moving direction, 0 to 3). - For each instruction of the code executed, the snake will also make a move. With the exception of
ret,branch,switchandphiinstructions. - The game is won if your code could control the snake to eat exactly 64 foods before collapsing into walls, intersecting with self, having illegal inputs or exceeds the time limit.
Now let’s head into the misc part, which is to write the code that wins the game.
Misc
Actually, there are a few more constraints:
- You can only submit LLVM IR (although Clang supports more language).
- The submitted LLVM IR should be less than 4096 bytes long.
- The submitted code will be optimized via
-O3by Clang first.
And before you read the next part of the write-up, I recommend you to try playing the misc part of the game, as I think it is a pretty fun puzzle.
Now, there’s definitely more than one solution, but let’s discuss the general direction:
- It is impossible to write code that can play the game perfectly, as there is a slight chance that the food is spawned in front of the snake. And since loading the food position takes in one tick, within that tick the food is already consumed, and the load will return the location of the next food. Since we require exact 64 foods, missing count meaning losing the game.
- It is impossible to keep track of the full snake body location (or even, any location of the snake), if the snake’s move is not deterministic. Other than the constraints of the size of the program, there’s simply no support of
allocaor any other primitives that allows the code to keep track of the state. Plus the issue we mentioned above. - It is impossible to win with a completely fixed pattern (no branching), because the timers are set so that traversing the entire board 64 times is not possible.
That gives us some important observations:
- We still need to have some kind of patterns to help us navigate through the game board without collapsing into self. Especially when the length is untrackable, we need to make sure the pattern works even when the body is full size (64).
- The solution can only work by chance. Since the food placement is random for each game, the solution working or not should be a distribution. And we need to find a solution that works at least frequently (as the server has PoW limit).
- We need to make use of branching instructions, as they don’t advance the game. In particular, the
switchinstruction, since it allows branching via values (and most of the values are within the range of 256).
And the rest is trial and error, and of course optimization. It is recommended to have a way (either through debugger or instrumentation) that can dump the state of the game, to better help debugging your code.
The author’s solution can be found on the official GitHub repository.

